


Introduction: Why Autoscaling GenAI Inference Is a Hard Problem
Deploying a GenAI model for a few hundred users is relatively easy. But as soon as you cross into the realm of thousands or millions of users, the change management becomes difficult and autoscaling becomes the real pain.
Suddenly, everything becomes harder:
- Inference latency spikes during peak hours.
- GPUs either sit underutilized or overloaded.
- Infrastructure costs spiral due to overprovisioning or reactive scaling.
- SLAs become impossible to enforce.
Delivering fast, reliable, accurate, and cost-effective inference at scale isn’t just about provisioning more hardware it’s a systems design problem. GenAI introduces new challenges that demand intelligent orchestration, resource-efficient scheduling, real-time autoscaling, and infrastructure that adapts dynamically to workload behavior.
In this blog, we’ll break down:
- The core challenges of scaling GenAI inference
- How Simplismart’s infrastructure-native stack is designed to meet them
- The technical differentiators that make sub-60s scaling, GPU sharing, and SLA compliance possible at scale without compromising on the model accuracy
The Challenge: Why Autoscaling GenAI Inference Isn’t Just ‘More GPUs’
Scaling from thousands to millions of users is not a linear exercise; it requires a re-architecture of how inference workloads are deployed and managed. Here are five systemic challenges Simplismart frequently encounters across production GenAI deployments across many use cases.
1. Cold Start Latency
Large models like Llama, Deepseek, and Qwen variants can take ~10 minutes to load on fresh pods. In bursty traffic patterns, this leads to significant user-facing latency or failed requests.
2. Inefficient GPU Utilization
With dedicated model-to-GPU allocation, especially in multi-model or low-QPS workloads, GPUs sit idle for extended periods burning cost without delivering throughput.
3. Slow and Reactive Autoscaling
Traditional autoscalers rely on lagging indicators such as CPU and GPU utilization, which only trigger scale-up after system stress has already impacted latency or throughput. These autoscalers aren’t designed for the bursty, high-variance nature of GenAI traffic.
What they miss:
- Real-time throughput trends (tokens/sec, requests/sec)
- Active concurrency (number of in-flight requests or sessions)
- Latency headroom (P95/P99 inference latency thresholds)
- Traffic slope (rate of change in request volume)
Without these signals, traditional systems scale too late, leading to cold starts, SLA violations, and user-facing latency spikes.
4. SLA Violations and Lack of Observability
Meeting latency or throughput SLAs requires end-to-end visibility into queuing delays, pod warmup times, GPU load, autoscale rules, and the number of user requests. In traditional stacks, GenAI workloads operate with limited visibility, and teams often discover issues only after performance degrades.
5. Accuracy Degradation at Scale
Optimizing for speed and cost often comes at the expense of output quality. When scaling inference, many teams adopt aggressive quantization (int4/int8), pruning, or that can reduce the model’s accuracy.
Bottom line: Traditional inference stacks weren’t built to handle the bursty traffic patterns, large memory demands, strict SLA requirements like low latency and high throughput, all while keeping run costs under control for modern GenAI workloads.
The Simplismart Stack: Infrastructure That Thinks Like Your Model
Simplismart’s architecture is a new technology built from the ground up to scale GenAI inference workloads intelligently and efficiently. It’s not just a wrapper over Kubernetes; it’s a model-aware, workload-native orchestration layer deeply integrated with inference runtime characteristics.
Here’s how the stack breaks down:
1. Infrastructure Orchestration Layer
This layer manages the lifecycle of model-serving infrastructure i.e. scaling, placement, and provisioning across cloud and on-prem environments
- Sub-60s Pod Autoscaling: Models can scale from zero to ready-to-serve in under 60 seconds avoiding cold start penalties during bursty traffic.
- Predictive Traffic-Aware autoscaling: Goes beyond reactive autoscaling by using request rate trends, concurrency trends, and latency headroom to scale proactively before load spikes hit.
- Kubernetes-Native & BYOC Friendly: Designed to run on any Kubernetes or bare metal cluster, whether hosted on AWS, GCP, Azure, or in air-gapped enterprise environments.
- Terraform-like Deployment APIs: Infra provisioning is code-defined and versioned. This ensures reproducibility (same infra setup every time, across environments) and governance (trackable changes, RBAC, policy enforcement) critical for regulated or large-scale enterprise teams.
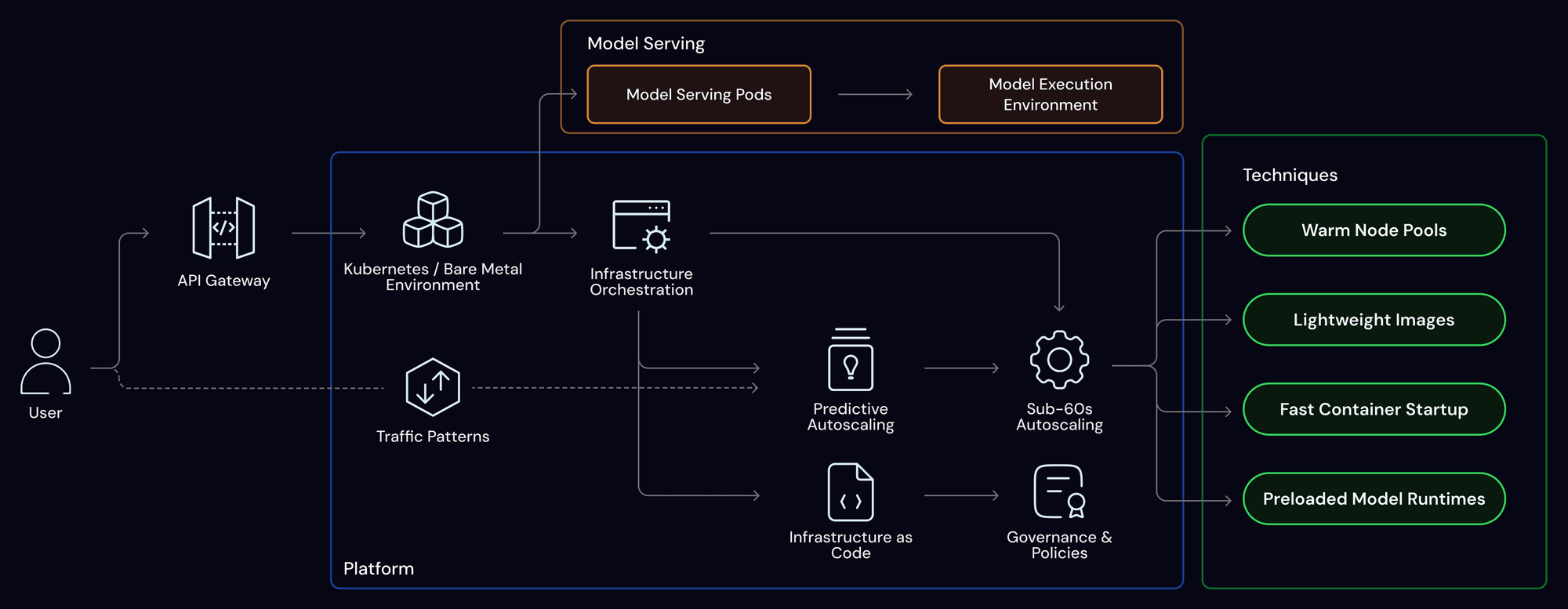
2. Application Serving Layer
At the heart of Simplismart's architecture is a centralized, intelligent serving layer which acts as a single entry point for all inference traffic and dynamically routes requests to the right model instance based on request context.
- Model-Agnostic and Centralized: The serving layer doesn’t need to be redeployed per model. It supports routing across any number of models or model variants (e.g., Llama, Deepseek, internal fine-tuned versions) from a single deployment.
- Context-Aware Routing: This layer makes routing decisions based on prompt size, model availability, and fallback logic (e.g., route long-context requests to Deepseek, fallback to smaller models if under load).
- Multi-Tenant Support: Supports serving different user groups (e.g., product teams, business units, or regions) with isolated routing paths, quota limits, or model preferences without duplicating infrastructure.
3. Model-GPU Interaction Layer
This layer optimizes how models are loaded, executed, and scheduled on GPU resources maximizing both performance and hardware efficiency.
- GPU optimization via:
- Quantization (int4/int8, GPTQ)
- CUDA Graphs for reduced Kernel launch overheads
- FlashAttention 2/3 for memory-efficient attention computation
- Multi-backend support: Works seamlessly with leading inference runtimes such as vLLM, TensorRT-LLM, and Simplismart's own high-performance engine, ensuring flexibility and maximum throughput across different model types and deployment targets.
- Dynamic GPU Partitioning: Enables multiple models to be co-hosted on a single GPU by intelligently slicing memory and compute boundaries. This is especially valuable for lightweight workloads or variant-rich deployments, where dedicating full GPUs would otherwise lead to underutilization.
4. Observability and SLA Enforcement
This layer provides deep, real-time visibility into inference performance and resource behavior, ensuring SLA commitments are met even under unpredictable load conditions
- End-to-End Telemetry: Tracks several critical metrics such as P50/P95 latency, pod startup times, GPU utilization, inference throughput broken down by model or endpoint.
- Automated Alerts & Proactive autoscaling Triggers: Integrates with autoscalers to trigger proactive infrastructure actions such as scale-up model replicas or traffic rerouting before user-facing degradation occurs.
- Enterprise-Ready Dashboards: Whether you're an SRE, infrastructure engineer, or part of the MLOps team, debugging and governance should never be a bottleneck. The platform includes out-of-the-box observability panels, real-time performance metrics, and audit trails making it easy to trace issues, monitor health, and enforce governance with minimal operational friction.
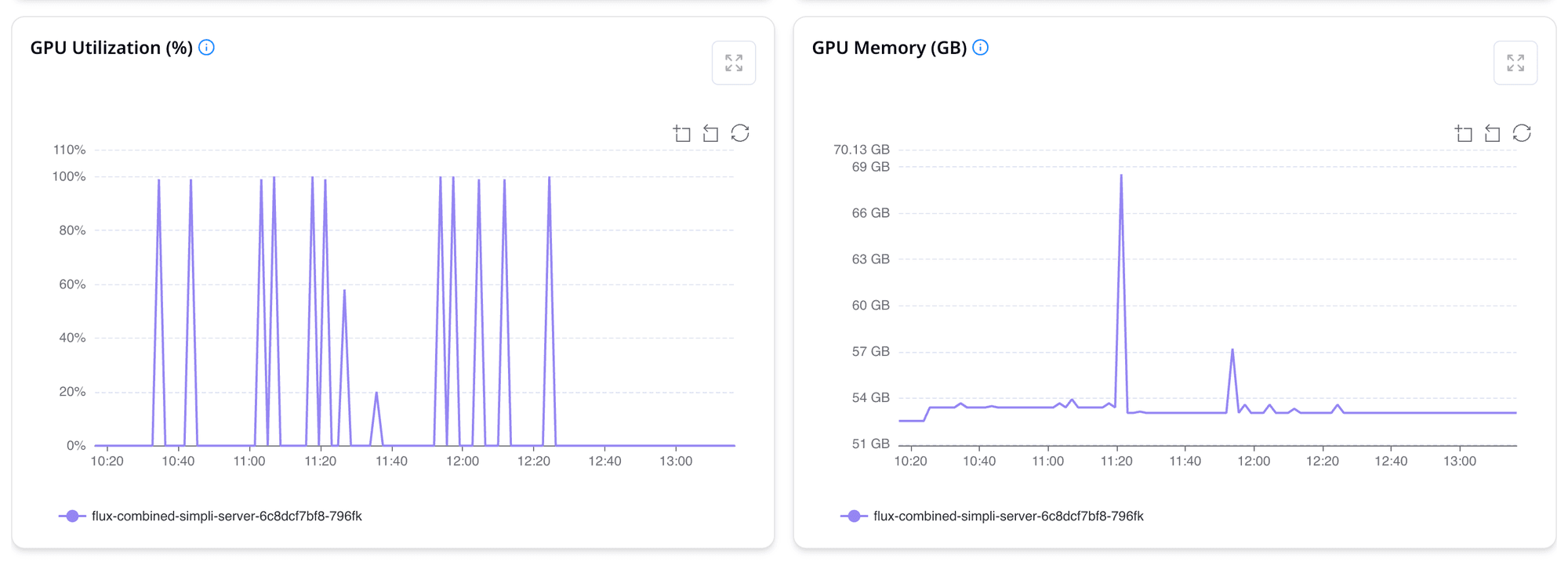
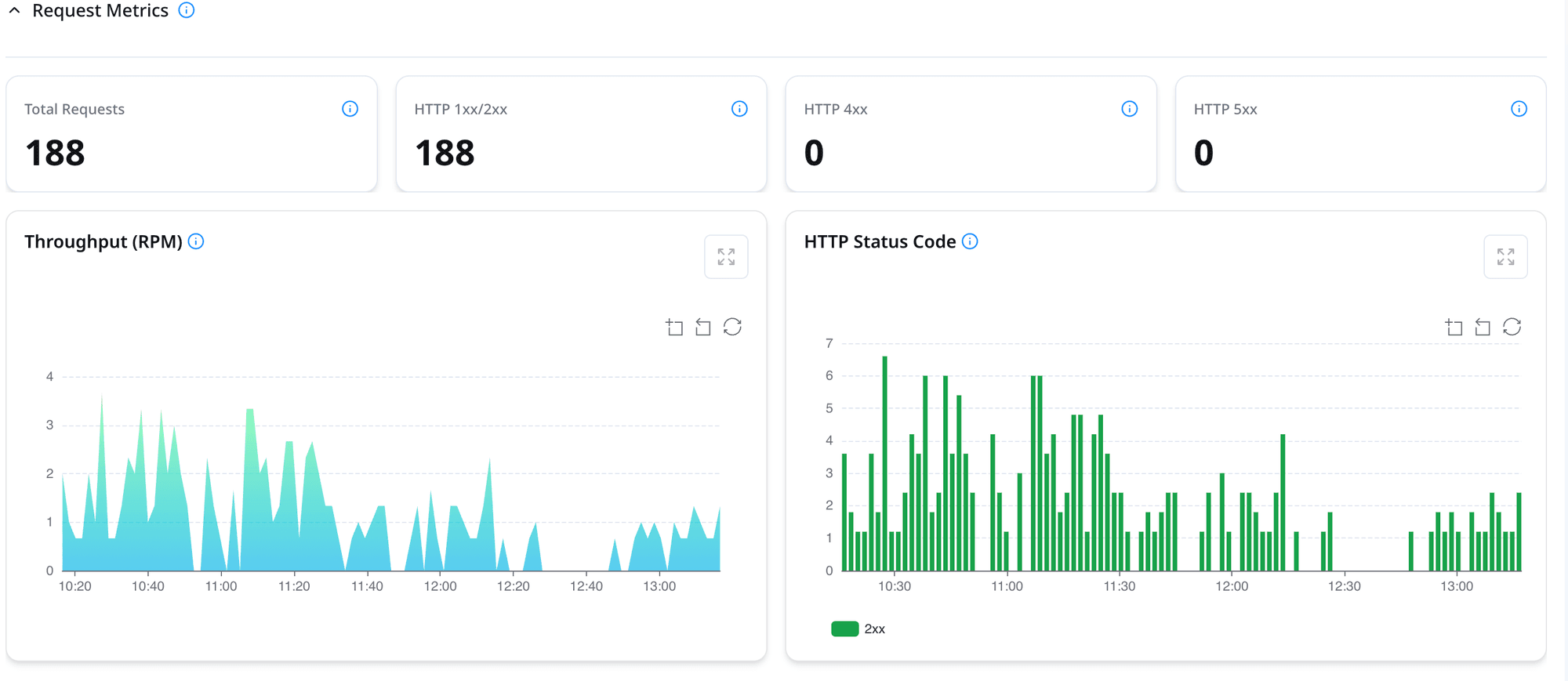
Closing Thoughts: Scaling Isn’t About Hardware It’s About Architecture
Inference at scale isn’t just a serving problem it’s a coordination problem. It’s about:
- Matching workloads to resources in real time
- Abstracting infra complexity without sacrificing performance
- Giving teams visibility and control without the overhead
Simplismart enables teams to do exactly that with a platform designed for the unique demands of GenAI workloads.
So whether you're growing from 1k to 100k users, or planning to serve millions, Simplismart ensures:
- Predictive autoscaling
- Sub-minute pod readiness
- GPU efficiency at scale
- SLA-bound performance across workloads
Ready to make your GenAI workloads production-grade? Talk to us.



