


When NVIDIA's H200 was launched, it promised memory-rich compute for the most demanding Generative AI models. And while early benchmarks give us valuable insights into raw performance metrics, at Simplismart we went one step further: deploying actual production inference workloads like DeepSeek on 8xH200 clusters.
This blog shares what it really takes to optimize, scale, and productionize Deepseek inference on the H200.
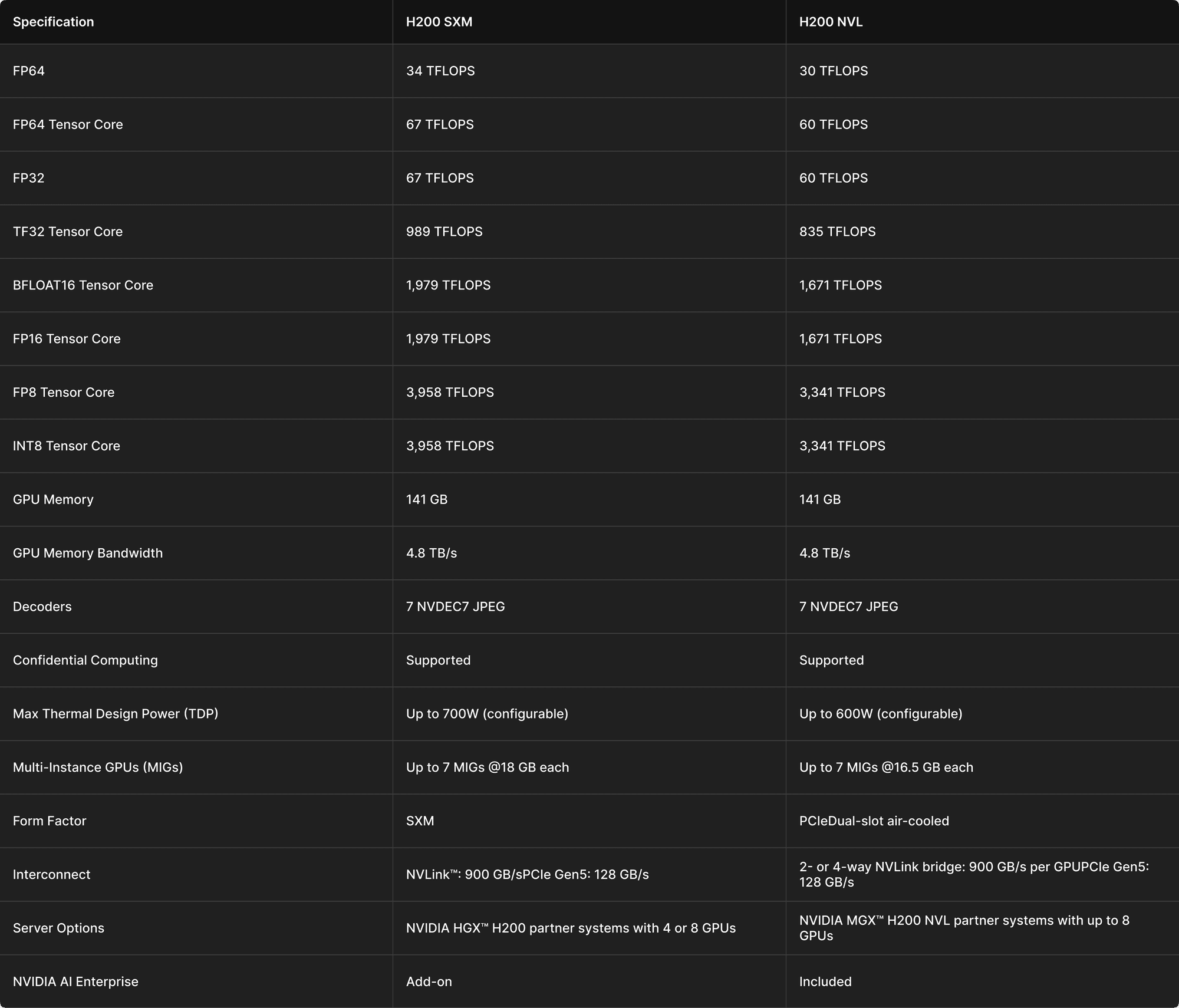
Why We Used H200s for DeepSeek R1 over H100s
“We needed high memory, fast token generation, and efficient KV cache reuse all at production-grade reliability.”
Deepseek R1 is a model family known for its reasoning capabilities and at 685 billion parameters, it’s one of the largest models in practical use. To serve DeepSeek reliably in production across varied batch sizes and user inputs, we needed:
- 141 GB VRAM per GPU to support long-context inference with large KV cache
- Higher memory bandwidth (4.8TB/s) to minimize throughput bottlenecks
- Improved KV cache locality and reuse for multi-turn conversations
- Support for FP8 quantization for flexible performance trade-offs
With this scale, NVIDIA H100s natively can’t serve large models like Deepseek. Even at FP8, DeepSeek R1’s weights alone take up around ~872 GB of memory to load, forcing a distributed setup across 16×H100s (2×8 nodes) and relying on data-parallel attention, a slow and complex architecture to orchestrate.
By contrast, H200s’ memory unlocks batch sizes and context windows that just weren’t feasible on H100s, especially for workloads like DeepSeek R1.
Simply put: H200 lets us serve these massive models much more natively, with less operational pain and higher throughput per dollar.
Our Deployment Stack
Here’s what a typical production deployment for DeepSeek on H200s looks like with Simplismart:
- Model: Deepseek R1, quantized to FP8 as provided officially by Deepseek
- Cluster: 8xH200 with NVLink + NVSwitch (1.1TB VRAM total)
- Engine: Simplismart’s proprietary high-performance inference engine optimized for LLMs
- Serving Orchestration: Multi-GPU partitioning with prefill decoding segregation
- Autoscaling: Token-throughput aware with warm-start support
Unlike most benchmarks, we optimize for token throughput per dollar, not just TPS.
Key Learnings in Production
1. H200 Shines When KV Cache Dominates
In long-context scenarios (e.g. ~30K token input), maintaining a large KV cache with faster prefills is essential. H200’s abundant VRAM lets us keep the cache resident, avoiding evictions and ensuring smoother, lower-latency inference.
Example:
- Input: 32,000 tokens
- Output: 2,048 tokens
- Resident KV cache enables sustained decoding without eviction:
→ Keeps more requests in-flight per GPU without eviction
→ Supports larger, more efficient batches at full context length
→ Drives ~1.5× higher throughput and ~25% lower cost per token
2. Batching is Key But Needs Smart Management
H200 allows ~64 continuous request batching but:
- Batch too large? You risk cold start and tail latency spikes
- Batch too small? You underutilize VRAM and memory bandwidth
We solve this with Simplismart’s adaptive inference stack:
- Disaggregated prefill and decode phases to improve queueing & utilization
- Latency budgets aware autoscaler
- Cache-aware routing based load balancer
This keeps latency SLOs predictable, even with massive workloads.
To maximize throughput for large models (100B+ parameters), the best results come from a combination of multiple GPUs and tackling the grid-search hell i.e. solving prefill disaggregation, KV cache management, dynamic batching, and intelligent request routing.
Closing Thoughts: More than the GPU, It’s the Stack
Most infra teams underestimate the complexity of production inference:
- Model & multi-GPU management
- KV cache lifecycle orchestration
- Cost-aware autoscaling
- Dynamic batching + routing
That’s what Simplismart does best.
If you're deploying 100B+ models like Deepseek, Mistral Large, Llama3-70B, we can help you scale it across H200 clusters without the infra pain.
Want to explore H200-powered inference with DeepSeek or Mistral Large?
We’ll help you test and deploy on Simplismart with H200 clusters. Talk to us.



