
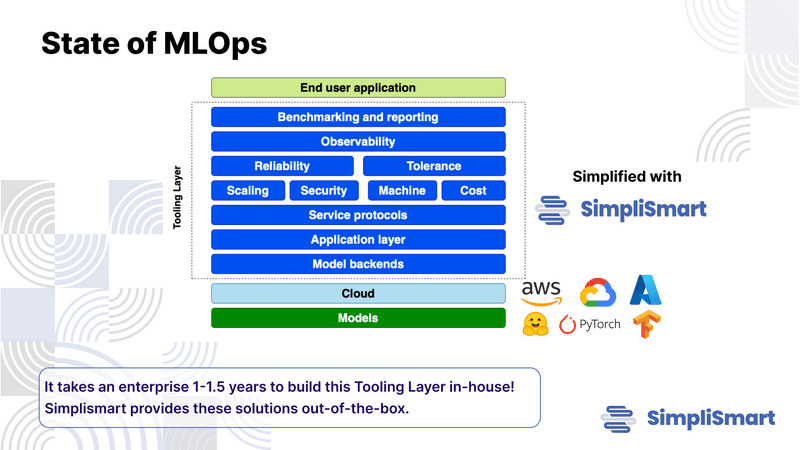
In the ever-evolving landscape of machine learning (ML), efficiency, scalability, and observability are paramount. Organisations are trying very hard to make efficient systems that can cater to their use cases and also have a positive ROI. Simplismart is a platform offering a comprehensive suite of solutions for ML model training, deployment, and observability. Simplismart has been able to achieve both quality and inference speeds with the most optimised cost structure.
Our Llama2-7B inference on A100 GPUs have a total token throughput of 11k per second. On top of it, we charge a measly amount of $0.15 per million tokens, making us the cheapest solution in the market.
So how did Simplismart achieve this?
Understanding each step in an ML Model Life cycle will give a deeper insight into how this is done:
Model Backend
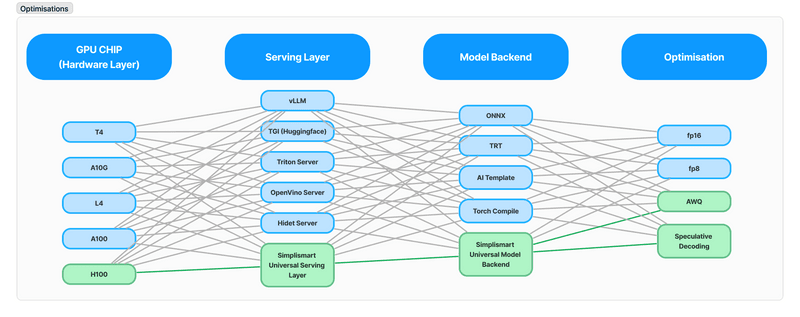
Simplismart's journey begins with developing its own model backend, where it has set new standards for efficiency and performance. Leveraging optimisations from the kernel level, Simplismart has tailored it to maximise the efficiency of Matrix-Multiplication operations, ensuring it is mapped with the most compatible kernel for each operation. Thus, minimizing computation time and resource utilisation.
Serving Protocol
In deploying models, communication protocols play a crucial role in determining performance. Simplismart eschews the traditional REST protocol in favour of gRPC, a high-performance Remote Procedure Call (RPC) framework. By leveraging Protocol Buffers and HTTP/2, gRPC facilitates efficient communication in distributed systems, significantly outperforming traditional REST-based approaches.
Serving Engine
At the heart of Simplismart's deployment strategy lies the Triton serving engine, optimised for NVIDIA GPUs. This enables Simplismart to achieve unparalleled performance gains, with Triton delivering a 28% speed improvement over alternatives like FastAPI. Moreover, Triton offers comprehensive observability features, allowing Simplismart to monitor performance metrics, VRAM usage, model management, and more, providing invaluable insights into system health and efficiency.
Observability
Simplismart uses Prometheus for the metric collection of all models and clusters. It collects metrics like:
- Node Pool health
- Cluster Health
- GPU Utilisations
- CPU Health
- RAM
- Storage usage
All these metrics are displayed on a Grafana Dashboard which allows users to make better machine arrangements and optimal resource allocation.
What do all the above improvements result in?
Simplismart has achieved unmatchable inference speeds with no compromise to quality. Other platforms only quantise models to improve their inference speeds. This often reduces the quality of the result. Simplismart has made optimisations at all three layers: Application Layer, Infrastructure Layer and Cloud layer. We have outperformed all available platforms in all, cost optimisation, result quality, and inference speeds.
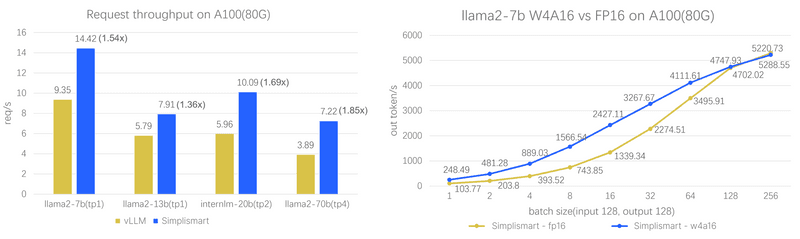
How Simplismart Inference Engine V2 can help streamline Generative AI deployments.
LLMs: The culmination of Simplismart's optimisations and strategic choices is exemplified by its impressive throughput metrics. Simplismart achieves a staggering throughput of 11,000 tokens per second for the llama2-7B model on A100 models and 9000 tokens per second on the Mistral model, showcasing its ability to easily handle large-scale inference tasks.

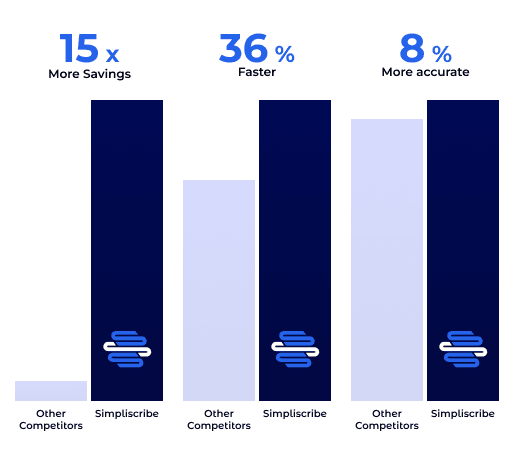
Simpliscribe (Speech-to-Text): Simplismart has achieved a remarkable 30x transcription speed improvement on Whisper, the open-source model by OpenAI. With our platform, a 30-second audio is transcribed in 1 sec on a T4 Nvidia GPU.
Diffusion Models: Simplismart has an impressive response time of just 2.2 secs for generating a 1024x1024 image using Stability AI’s Stable Diffusion XL (1.0). The diffusion model is highly efficient for higher step sizes in image generation.
Text-to-Speech: Simplismart has a real-time speed in speech generation using the open-source models Tortoise and XTSS. This has also empowered many companies to successfully build Voice bots that give a combined latency of just 700ms.
Don't believe it? Check out this post on how Vodex, a multi-million dollar business decreased latency and saved costs, developing its unit economics with Simplismart.
Conclusion
In conclusion, Simplismart stands at the forefront of innovation in the ML ecosystem, offering a holistic solution for model training, deployment, and observability. Through strategic optimisations, cutting-edge technologies like gRPC and Triton, and a relentless focus on efficiency, Simplismart is empowering organisations to harness the full potential of machine learning with unparalleled speed, scalability, and cost-effectiveness. As the demand for ML solutions continues to surge, Simplismart remains the trusted partner for those seeking to unlock the transformative power of AI.



