In this tutorial, we are going to build a Simplismart Q&A Chatbot. This chatbot will be equipped to answer any question regarding Simplismart.
But first, what is RAG?
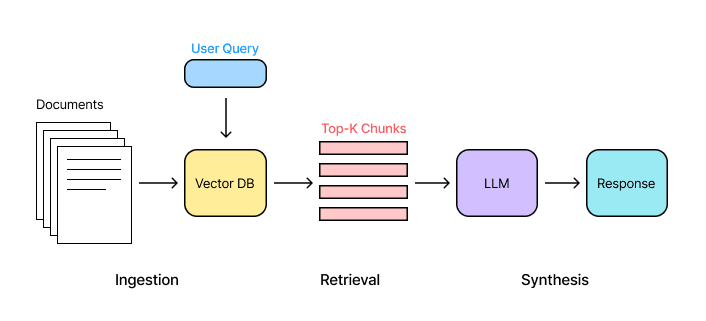
RAG stands for Retrieval Augmented Generation. It is an AI framework that enhances the response quality of large language models (LLMs) by providing external sources during the generation process. RAG is advantageous because it does not require training, reduces hallucinations, and ensures the generated responses are as contextually relevant as possible.
There are three main steps in the RAG pipeline:
- Ingestion involves converting external sources into chunked vector embeddings.
- Retrieval includes obtaining the top-k contextually relevant documents given a query.
- Synthesis implies generating a response given the additional context.
Therefore, RAG is a valuable method for efficiently providing chatbots with the necessary context to answer users’ questions more accurately.
What are "Guardrails" in AI?
AI guardrails are safety mechanisms that ensure that AI applications follow guidelines that meet ethical and societal standards. Guardrails also ensure that user interactions with LLMs are protected and that the generated responses are valid, accurate, and professional.
Guardrails AI
Guardrails AI is an open-source Python framework that can be used to build reliable AI applications by setting up input and output “guards” that mitigate any risks, vulnerabilities, and unethical output generated by the LLM. It serves as a wrapper around LLM applications. Some of the common “guards” that can be set using Guardrails AI include:
- Ensuring profanity-free LLM output.
- Ensuring any summarisation is faithful to the original text.
- Checking the validity of generated code, SQL, URLs, etc.
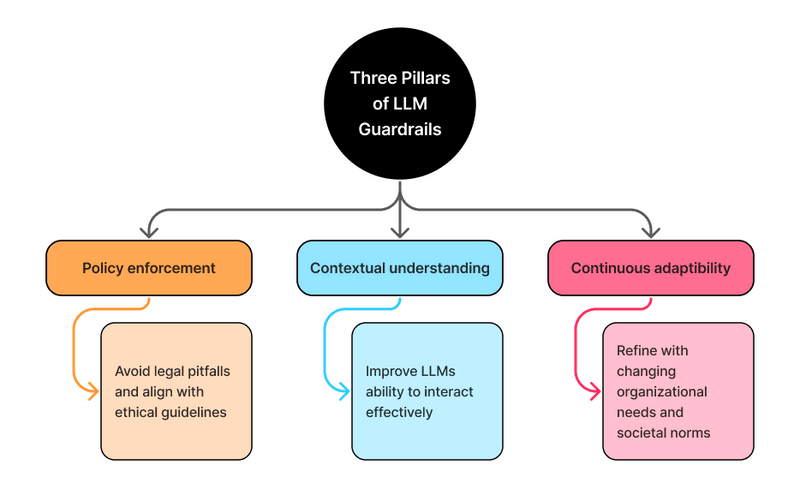
Therefore, Guardrails AI can ensure that conversations between the user and the chatbot are safe and ethical. The Guardrails AI documentation contains other use cases and code snippets.
Step-by-Step Tutorial
In this tutorial, we are going to build a Simplismart Q&A Chatbot. This chatbot will be equipped to answer any question regarding Simplismart and validate user input.
Briefly, the steps would be as follows:
- Load some documents into a vector database. You need to do this only one time to build the chatbot.
- Retrieve relevant context from the vector database based on user query. (Using Langchain)
- Generate and print a response given the user query and additional context (ft. SimpliLLM)
- Add guardrails to ensure the generated response has a valid URL link to the Internet source from which it retrieved information (ft. Guardrails AI).
Requirements and Installations
Firstly, ensure that you have pip, python, and an IDE (ex: VSCode) on your system. Using pip, you will install the necessary LangChain, OpenAI, and Guardrails packages as follows:
pip install langchain
pip install langchain-core
pip install langchain-community
pip install langchain-openai
pip install openai
pip install guardrails-ai
guardrails hub install hub://guardrails/gibberish_text
We will also require an OpenAI account and API key. Once you generate the API key, save the key in your environment variables as ‘OPENAI_API_KEY’ (click here). In order to use the API, there also needs to be money in the account. A fee of about $5 should be more than sufficient for testing purposes.
We are also going to need to create a directory of Simplismart documents. So, in our project folder, we can add:
- A directory called “data” containing all the markdown files associated with Simplismart.
- A Python file called “rag-chatbot.py”
At the top of the Python file, we will first import all the modules we require.
# Required packages
from langchain_community.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_core.prompts import PromptTemplate
from openai import OpenAI
from guardrails.hub import GibberishText
from guardrails import Guard
import os
import shutil
Now, we are ready to delve into the first step.
Step 1: Creating the Vector Database
Firstly, we will create our load_documents() function to load the documents from our data folder using LangChain’s DirectoryLoader class.
DATA_PATH = "data" # path to data folder
def load_documents():
loader = DirectoryLoader(DATA_PATH, glob = "*.md")
documents = loader.load()
return documents
Now, we must split the documents into smaller chunks of 1000 characters with a 500-character overlap. Using LangChain’s text_splitter module, we can create a function chunk_documents() that achieves the above. This function also prints the number of chunks into which the documents were split.
NOTE: Feel free to edit the chunk_size and chunk_overlap parameters based on the structure of your documents!
def chunk_documents(documents: list[Document]):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 500,
length_function = len,
add_start_index = True
)
chunks = text_splitter.split_documents(documents)
print(f"I have split {len(documents)} documents into {len(chunks)} chunks.")
return chunks
Then, using LangChain’s Chroma database module and OpenAI’s vector embeddings function, we can create a function save_to_db() that creates a vector database out of the embeddings made from the document chunks. Upon successful execution, we will also print “Created database.”
DB_PATH = "chroma" # path to vector database
def save_to_db(chunks: list[Document]):
if os.path.exists(DB_PATH): # shut down existing db
shutil.rmtree(DB_PATH)
db = Chroma.from_documents( # create new db
chunks, OpenAIEmbeddings(),
persist_directory = DB_PATH
)
print("Created database.")
return db
Finally, we can combine the above three functions into a generate_db() function as follows:
def generate_db():
docs = load_documents()
chunks = chunk_documents(docs)
db = save_to_db(chunks)
return db
def main():
db = generate_db()
main()CHECKPOINT 1
Now, we can run our Python file by running the "python3 rag-chatbot.py" command on our terminal and get an output as follows:

The vector database should be successfully created and put in the DB_PATH we mentioned above. We have successfully completed the first step!
Step 2: Querying the Vector Database
Now that we have created the vector database, we should be able to retrieve context from it given the user’s query. So, we can create a get_context_from_db() function that runs a similarity search, retrieving the top 3 documents that are most contextually relevant to the user’s query.
def get_context_from_db(db: Chroma, query: str):
documents = db.similarity_search(query, k = 3)
context = "\n\n-----\n\n".join(doc.page_content for doc in documents)
return contextCHECKPOINT 2
Let us edit our main() function as follows:
def main():
db = generate_db()
context =
get_context_from_db(db, "What is Simpliscribe?")
print("\n\n-----\n\n" + context
+ "\n\n-----\n\n")
main()
Upon running our Python file again, the function outputs the top 3 chunks that are most contextually relevant to the query, “What is Simpliscribe?”.
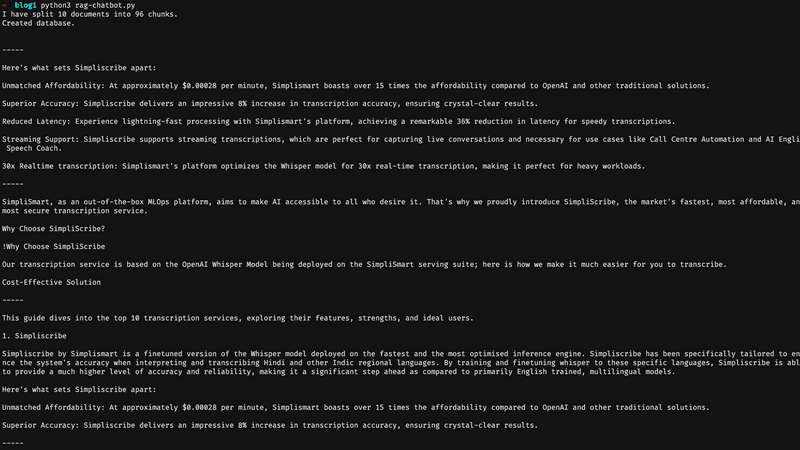
If your output looks something like this, you are done with step 2!
Step 3: Generating and Printing a Response
Moving on to step 3, we need to generate a response given the query and the relevant context. To do this, we first need to set up our client, which we can do using SimpliLLM, our super-fast inference engine for running LLMs.
First, you must obtain your token and LLM URL from the Simplismart team. Contact the sales team here to get access!
Now, update the main() function as follows:
def main():
db = generate_db()
# SET UP
token = "<Your Token Here>"
client = OpenAI(base_url = "<Your LLM URL here>", api_key = token,
default_headers = {"username":"demo"})
opening_statement = "Hi! You can ask me anything about Simplismart."
messages = [
{"role": "system",
"content": """You are a helpful chatbot that answers the user's questions based on given context."""},
{"role": "assistant", "content": opening_statement}
]
main()"messages” will be used to keep track of conversation history so that the chatbot can respond contextually.
Now, we also need a complete_chat() function that accepts an OpenAI() client and previous messages to generate a completion (response). SimpliLLM supports Llama and Mistral, so for this demonstration, we are going to use LLama 3.
def complete_chat(client: OpenAI,
messages: list[dict[str, str]]):
response = client.chat.completions.create(
model = "llama3",
messages = messages,
temperature = 0.2,
stream = True
)
return response
We should also create a prompt template that can be used to feed the context and question to the client for response generation.
PROMPT_TEMPLATE = PromptTemplate.from_template("""
Answer my question given the following context and your own knowledge.
-----
{context}
-----
Now, here is my question: {question}
""")
Now, using all these elements, we can extend our main() function to enable an interactive, conversational CLI chatbot that accepts user input and prints the generated output.
def main():
db = generate_db()
# SET UP
token = "<Your Token Here>"
client = OpenAI(base_url = "<Your LLM URL here>", api_key = token,
default_headers = {"username":"demo"})
opening_statement = "Hi! You can ask me anything about Simplismart."
messages = [
{"role": "system",
"content": """You are a helpful chatbot that answers the user's questions based on given context."""},
{"role": "assistant", "content": opening_statement}
]
# INTERACTION
print("\n" + opening_statement + "\n")
while True:
# user input
question = input("> ")
if question == "quit":
print("Goodbye!")
break
print("\n")
context = get_context_from_db(db, question)
prompt = PROMPT_TEMPLATE.format(context = context, question = question)
messages.append({"role": "user",
"content": prompt})
# generated output
response = complete_chat(client, messages)
print(response.choices[0].message.content)
messages.append({"role": "assistant",
"content": response.choices[0].message.content})
print("\n")
main()CHECKPOINT 3
Now, if you run the Python file, your output should look something like this:
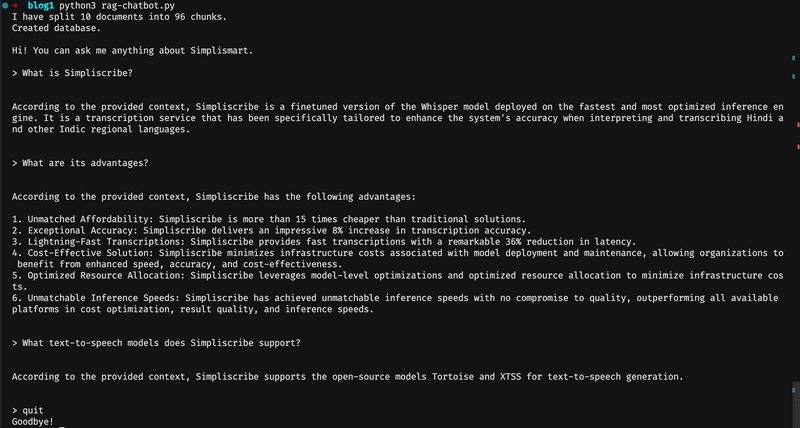
We are done with the third step!
Step 4: Adding Guardrails
Now, as a final step, we want to make sure that user input is actually valid and not gibberish. This way, we can prevent searching documents for context that doesn’t exist. So, let us edit our main() function as follows:
def main():
db = generate_db()
# guardrail set up
guard = Guard().use(GibberishText, threshold = 0.5,
validation_method = "sentence", on_fail = "reask")
# SET UP
token = "<Your Token Here>"
client = OpenAI(base_url = "<Your LLM URL here>", api_key = token,
default_headers = {"username":"demo"})
opening_statement = "Hi! You can ask me anything about Simplismart."
messages = [
{"role": "system",
"content": """You are a helpful chatbot that answers the user's questions based on given context."""},
{"role": "assistant", "content": opening_statement}
]
# INTERACTION
print("\n" + opening_statement + "\n")
while True:
# user input
question = input("> ")
if question == "quit":
print("Goodbye!")
break
print("\n")
guard.validate(question) # guardrail validation
context = get_context_from_db(db, question)
prompt = PROMPT_TEMPLATE.format(context = context, question = question)
messages.append({"role": "user",
"content": prompt})
# generated output
response = complete_chat(client, messages)
print(response.choices[0].message.content)
messages.append({"role": "assistant",
"content": response.choices[0].message.content})
print("\n")
main()
CHECKPOINT 4
Now, if you run the Python file, your output should look something like this:
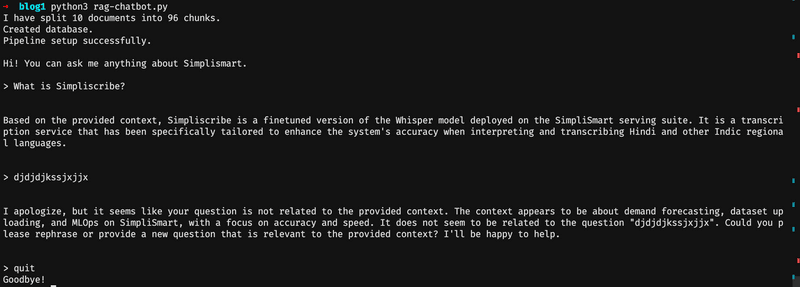
We are done with building our chatbot!
Conclusion
Every enterprise today is attempting to incorporate LLMs into its platform to enhance its usability—and what better way than by building a chatbot?
Chatbots can help enterprises in many ways:
- Customer support chatbots provide 24/7 assistance and can provide detailed, personalized, accurate responses to users’ questions.
- Marketing chatbots can be used to generate leads and advertise promotional campaigns, sales, discounts, etc.
- Internally, chatbots can be used for HR and IT to automate onboarding (while maintaining personalization) and provide technical assistance/troubleshooting.
- Financial chatbots can also be used internally, within the enterprise, to process invoices and answer financial queries.
RAG chatbots are very versatile because they enable improved accuracy, are scalable, flexible, efficient, and provide an enhanced user experience. As the enterprise’s knowledge base grows and changes, RAG chatbots can easily adapt without spending much company resources and time on training and fine-tuning. Implementing guardrails further ensures that the LLM produces production-quality output so that all conversations with users are controlled, safe, and ethical.
With this knowledge, you are now equipped to integrate a robust and secure RAG chatbot into your enterprise, leveraging the latest advancements in AI to drive success and innovation. If this tutorial seems interesting, you can also learn how to build a voicebot here.


