

FLUX.1 Kontext-dev model brings native image-to-image editing to users with a 12-billion parameter MMDiT Architecture that understands context without any external adapters. At Simplismart, we are serving this model via a production-ready API that delivers 6x faster inference than baseline implementations.
What Makes Flux.1 Kontext Dev Unique
The family of FLUX.1 Kontext models treat images like language. By feeding reference images into the model just like text words, it eliminates the need for fine-tuning and solves the biggest headache in AI editing, which is keeping a character's face consistent while changing everything else around them.
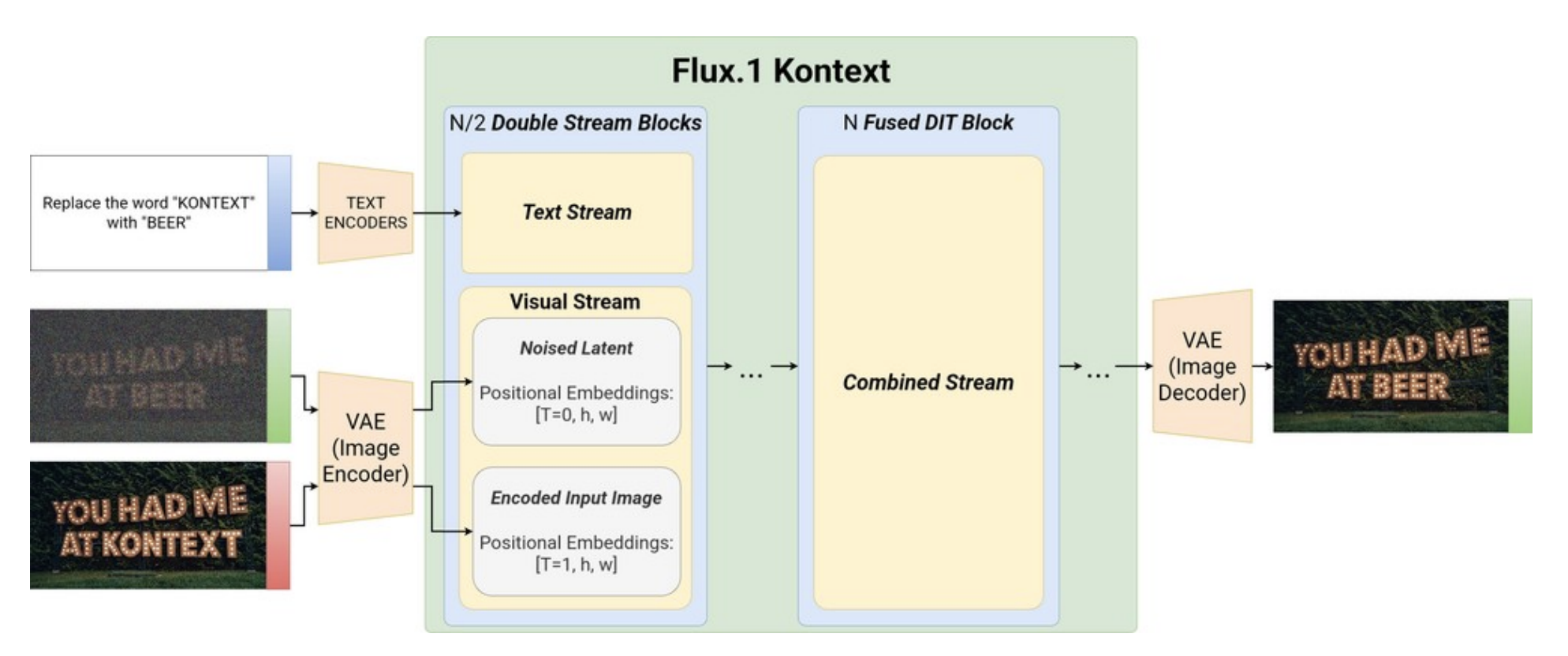
Unified Architecture via Sequence Concatenation
Traditional diffusion-based editing pipelines often rely on separate models or specialized adapter branches for tasks like inpainting, style transfer, or character editing. Flux Kontext takes a different approach by treating all inputs like text tokens, image latents, reference images, and other contextual signals as a single unified token sequence. These tokens are concatenated and processed together inside one large transformer, similar to how LLMs extend context with additional text. This eliminates the need for external adapter networks and creates a flexible, general-purpose editing architecture.
In-Context Editing Without Fine-Tuning
Instead of requiring LoRA training or full model fine-tuning to personalize a subject, Flux Kontext performs “in-context learning” directly from the reference images provided at inference time. The model extracts identity, style, and object features on the fly and uses them as conditioning tokens within the transformer. This enables it to insert, modify, or preserve visual concepts without requiring parameter updates, allowing for zero-shot personalization and reference-guided editing with high fidelity to the input image.
Superior Identity Preservation and Drift-Free Iterative Editing
A major challenge in existing diffusion editors is “visual drift”, where character appearance degrades or changes after multiple rounds of editing. Flux Kontext is specifically trained for multi-step workflows, giving it exceptional robustness to iterative prompts. Its token-based representation preserves high-frequency details and consistent features across turns, making it well-suited for storytelling, storyboard creation, and long editing sessions where identity stability is essential.
Flow Matching for Faster and More Stable Generation
Unlike classical diffusion models that require many noisy denoising steps, Flux Kontext uses a Flow Matching objective. This trains the model to follow a smooth, continuous path from noise to the final image by learning an optimal velocity field. While not literally a straight line, this path is significantly more direct than DDPM/DDIM sampling, allowing Flux Kontext to produce high-quality images in far fewer steps. The result is faster inference, greater stability, and stronger performance in reference-guided editing.
Simplismart's Performance Optimizations for Flux Kontext API
Baseline Performance: Standard Flux Kontext dev implementations average 15 seconds per 1024x1024 generation on H100 GPUs.
Simplismart Optimization: Our production deployment achieves 2.4 seconds end-to-end through targeted optimizations:
FlashAttention-3 (FA3)
FA3 is optimized for Hopper (H100) and provides the largest performance gain. Key improvements include:
- 40% lower memory usage via tiled, IO-aware attention
- Fused attention kernel combining QKV projection, scaling, softmax, and value aggregation
- FP8 compute support, enabling faster matmuls and lighter KV-cache
- Asynchronous data movement using Hopper’s TMA and warp-specialized attention flows
- Major latency reduction for Flux Kontext’s long text+image sequences
FA3 alone contributes a 2.5–3× speedup for the attention stack.
Torch Compile Optimization
TorchCompile adds further acceleration through graph-level optimizations:
- Operator fusion for transformer subgraphs (Linear → GELU → Linear, QKV → Attention → Proj)
- Dynamic-shape compilation for 512–1024 resolutions
- Memory layout optimization to improve tensor-core throughput
- Autotuned kernels tailored to A100, H100, and other Nvidia GPUs.
- Reduced kernel launch overhead and fewer Python-level dispatches
This contributes an additional 25–30% speedup across the full diffusion pipeline.
Getting Started with Simplismart Platform
There are two primary ways to leverage Flux Kontext API on the Simplismart platform:
- Pay as you go: Access Flux kontext on our shared endpoint, perfect for experimentation and variable workloads. Check out our pricing page to know more.
- Dedicated Deployment: Full control over the deployment, ideal for high-volume production applications where you can optimize the deployment to your specific requirements. Refer to this documentation to learn how to deploy your model on the Simplismart infrastructure or your own cloud.
1. Try Flux Kontext API on the Playground
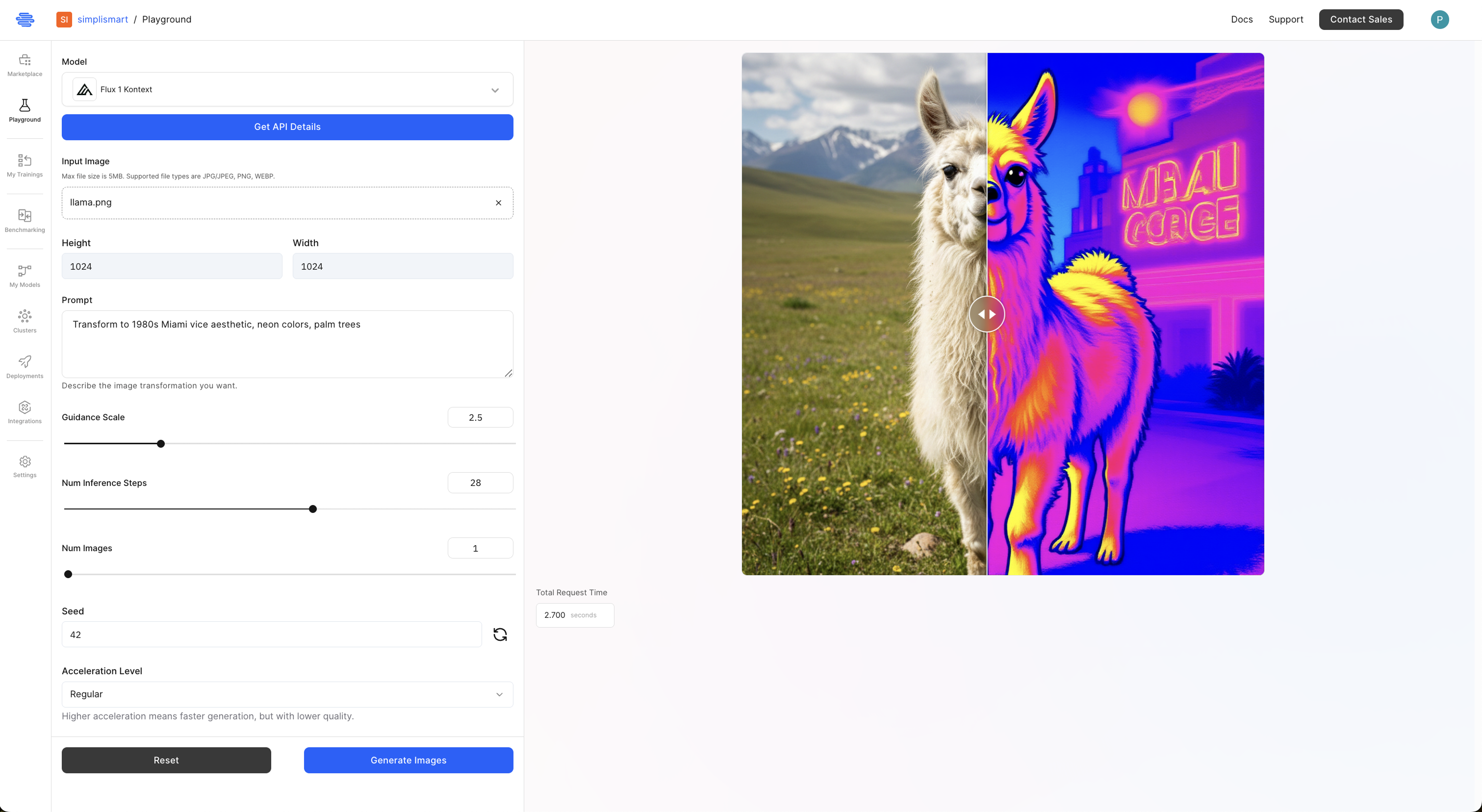
The easiest way to experience the model is through the Simplismart Playground, where we host multiple models across modalities. You can test Flux Kontext immediately without any installation.
2. Build a Custom App using Flux Kontext API
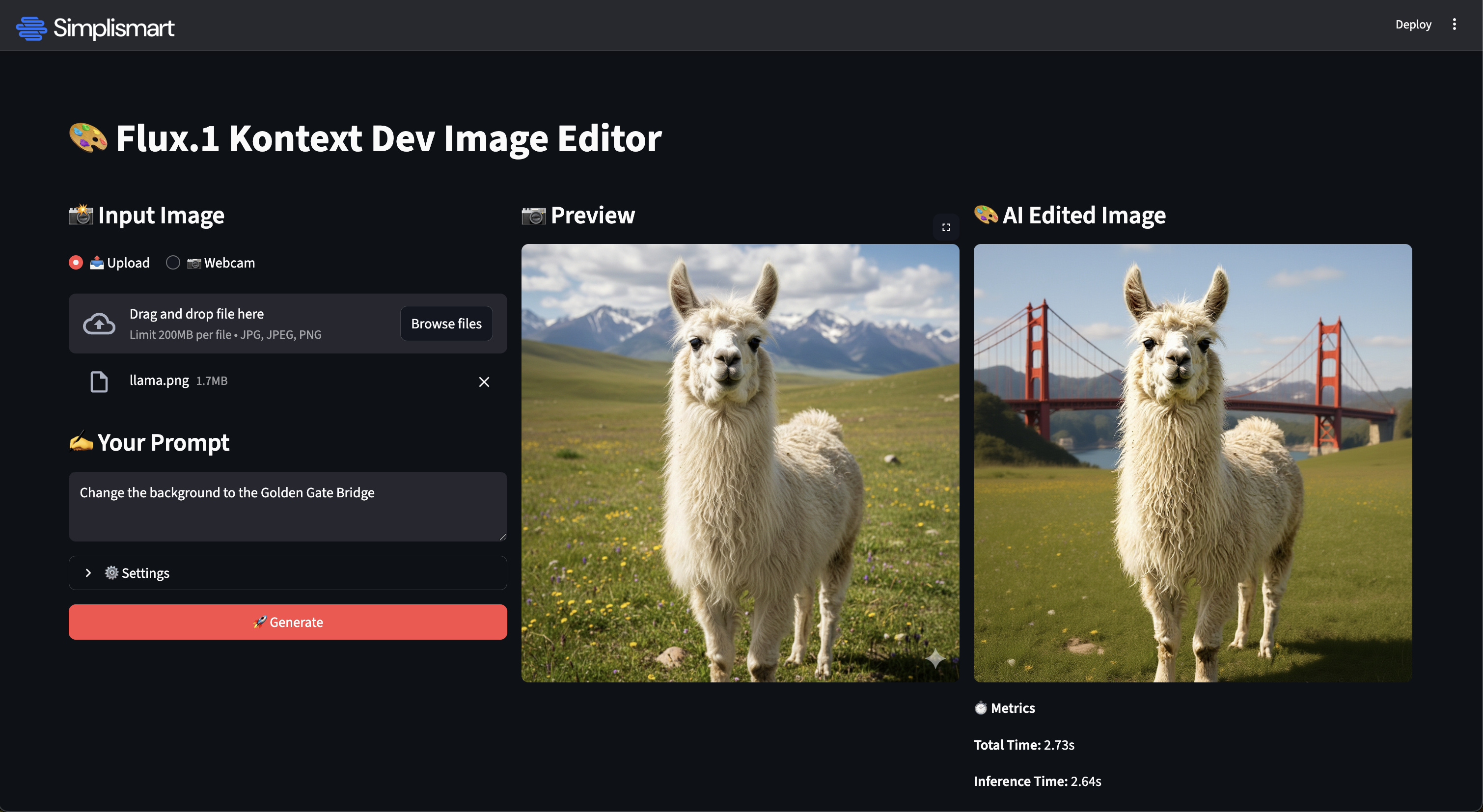
To demonstrate how to integrate the API into your codebase, we've created an image generator application using Streamlit.
Prerequisites:
- Get Endpoint URL: Visit Simplismart Playground > Select "Flux Kontext" > Click "Get API details" > Copy the endpoint URL.
- Get API Key: Navigate to Settings → API Keys → Generate new key → Copy the API key
Installation Steps
1. Clone the cookbook repository
git clone https://github.com/simpli-smart/cookbook/
cd flux.1-kontext-dev
2. Create and activate a virtual environment (optional)
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
3. Install dependencies
pip install -r requirements.txt
4. Configure environment variables
cp .env-template .env
5. Open .env and paste your Endpoint URL and API Key
SIMPLISMART_BASE_URL=your_endpoint_url_here
SIMPLISMART_API_KEY=your_api_key_here
6. Run the Application:
streamlit run app.py
This will launch a local interface where you can upload reference images and provide text prompts to see Simplismart’s blazing-fast inference speed in action.
Closing Thoughts
FLUX.1 Kontext-dev represents a shift in how we approach generative AI, moving from complex, multi-stage pipelines to unified, context-aware architectures. At Simplismart, our goal is to make new technologies production-ready. By slashing inference times from 15 seconds to under 2.4 seconds, we’re enabling real-time, interactive applications that were previously impossible.
Whether you're building the next generation of creative tools or integrating AI editing into your existing workflows, speed and quality no longer have to be a tradeoff.
Resource
- GitHub repo: https://github.com/simpli-smart/cookbook/flux.1-kontext-dev/
- API Docs: docs.simplismart.ai
- Flux Kontext Technical Paper: FLUX.1 Kontext arXiv:2506.15742
Ready to scale? Schedule a call with us to discuss how we can help solve your GenAI inference bottlenecks and optimize your production deployments.



