

Large Language Models (LLMs) have become the backbone of modern AI systems from customer support to code generation to enterprise workflows. But once you move from prototyping to production, a critical question arises: Do I rely on prompting and retrieval, or is it time to fine-tune?
This question is at the heart of our three-part blog series on fine-tuning. We’ll explore:
- When fine-tuning LLMs makes sense and how to do it efficiently (this post).
- How smaller, custom models when fine-tuned can outperform large, general-purpose LLMs on niche tasks.
- A hands-on walkthrough of how fine-tuning works on the Simplismart platform, with practical techniques and model examples.
By 2026, 40% of enterprise applications will feature task-specific AI agents up from less than 5% today (UC Today). To power these agents, enterprises need fine-tuned models that go beyond general-purpose capabilities. Fine-tuning is what enables this by aligning base LLMs with domain data, optimizing them for specialized tasks, and ensuring they perform reliably in real-world enterprise workflows.
When to Fine-Tune vs. Use RAG
Retrieval-Augmented Generation (RAG) and fine-tuning both let LLMs “learn” from your data, but they solve different problems.

- RAG is ideal for dynamic, up-to-date knowledge (e.g., policy Q&A).
- Fine-tuning is ideal for consistent style and domain-specific knowledge (e.g., legal drafting, branded content).
What are the Types of Fine-Tuning
Depending on your goal, you may choose one or more strategies:
- Supervised Fine-Tuning (SFT): Trains the model on prompt-response pairs. Ideal for improving task-following or alignment (e.g Customer support bots trained on past chat transcripts to respond exactly like humans)
- Instruction Fine-Tuning: Teaches the model to generalize across instruction formats. Used in Productivity assistants (Notion AI, Google Workspace AI) that handle any command: e.g.: “summarize this doc”
- Reinforcement Learning with Human Feedback (RLHF): Combines human preference data with reinforcement learning to align outputs. Includes methods like PPO (Proximal Policy Optimization) and newer approaches like DPO (Direct Preference Optimization). Used in moderation systems and conversational AIs where safer, more aligned responses are critical.
- Continued Pre-training: Next-token prediction over a large, domain-specific corpus. Useful for adapting general-purpose models to niche fields (e.g. in Healthcare fine-tuned on biomedical research, clinical notes, or proprietary data to answer niche medical queries).
- Parameter-Efficient Fine-Tuning (PEFT): Instead of updating all model weights, it adapts only small sets of parameters (e.g., LoRA, QLoRA, adapters). Great for resource-limited environments where you need efficiency without retraining the full model.
Notably, Gartner predicts organizations will use small, task-specific models three times more than general-purpose LLMs by 2027 (AI Magazine). This aligns directly with the growth of fine-tuning approaches.
Challenges Teams Face while Fine-tuning
Despite its benefits, teams often hesitate to fine-tune due to:
- Out-of-Memory Errors: 7B–70B parameter models push GPU memory limits.
- Training Instability: Long jobs crash without checkpointing.
- Fragile Infra: Few open-source stacks support retries, orchestration, or autoscaling.
- Limited Observability: Logs are minimal, making debugging painful.
- Data Quality Issues: Noise/bias in training new data worsens model reliability.
- High Costs: Multi-epoch training is GPU-intensive.
These blockers are why many enterprises either rely solely on prompting or outsource fine-tuning to providers often at high cost.
The Tooling Landscape in 2025
Teams today mostly choose between:
Unsloth
- ✅ Very fast single-GPU fine-tuning with QLoRA
- ✅ Memory efficient (4-bit QLoRA on consumer GPUs)
- ❌ Not production-grade, debugging complexity, limited long-sequence support
PEFT (Parameter-Efficient Fine-Tuning)
- ✅ Broad ecosystem support via Hugging Face
- ✅ Widely adopted and well-documented across the community
- ✅ Compatible with multi-GPU strategies (DDP, ZeRO, FSDP)
- ✅ Fully open source and flexible
- ❌ Not a scaling solution by itself performance at scale still depends on trainer/sharding setup
- ❌ Requires developer effort for efficient orchestration and throughput optimization
Hugging Face Transformers
- ✅ The most widely adopted library with a massive community and ecosystem support
- ✅ Flexible, works with PyTorch, TensorFlow, and JAX
- ✅ Easy integration with tokenizers, datasets, and Accelerate
- ❌ Can get heavy and bloated for simple use cases
- ❌ Production scaling often requires pairing with DeepSpeed/FSDP or custom infra
- ❌ High abstraction can hide performance bottlenecks
DeepSpeed (by Microsoft)
- ✅ ZeRO optimization enables training extremely large models efficiently
- ✅ Significantly reduces memory footprint while boosting throughput
- ✅ Strong compatibility with Hugging Face, Megatron, and other frameworks
- ❌ Steeper learning curve; requires deep familiarity with configs and tuning
- ❌ Debugging distributed training issues can be time-consuming
- ❌ More suited to research labs and infra-heavy teams than lightweight experimentation
Axolotl
- ✅ Known for stability, speed, and flexibility in fine-tuning pipelines
- ✅ YAML-driven configs make experiments reproducible and structured
- ✅ Strong community trust, frequently updated, and production-tested
- ❌ More complex setup than lighter frameworks like LLaMA-Factory
- ❌ Requires infra knowledge to leverage advanced optimizations (DeepSpeed, Flash Attention)
- ❌ Documentation is good but can lag behind rapid feature releases
How Simplismart Fixes the Stack
At Simplismart, we’ve built a training stack that makes fine-tuning work from experimentation to scale.
Built for Multi-GPU
- Scale across 2–16 GPUs with near-linear speedup
- Automatically shard datasets, sync gradients, checkpoint progress
Result: Train massive 7B–70B models without running into OOMs or failed restarts
Supports All Major Paradigms
- SFT, RLHF (DPO, PPO), PEFT (LoRA, QLoRA), RFT all included
- Compatible across all modalities: LLMs, VLMs, Speech to Text, and Media generation
Result: Flexibility to pick the right approach for your use case, with base foundation models of your choice
Infra Observability + Reliability
- Automatic job retries and resume-from-checkpoint capabilities prevent lost progress.
- Real-time visibility into loss, accuracy, and GPU utilization.
- Tight integrations with W&B and TensorBoard for experiment tracking.
Result: Debug faster, monitor smarter, and never lose days of training progress.
Fastest Time-to-Train at Scale
To evaluate our training speed, we benchmarked Simplismart’s training backend against Unsloth and PEFT in a controlled experiment.
Setup:
- Hardware: 1 × NVIDIA A100 (80 GB) node
- Model: 4-bit quantized Llama-3.2-11B-Vision-Instruct
- Dataset: ~600 MB chest X-ray dataset
- Steps: 300 fine-tuning steps
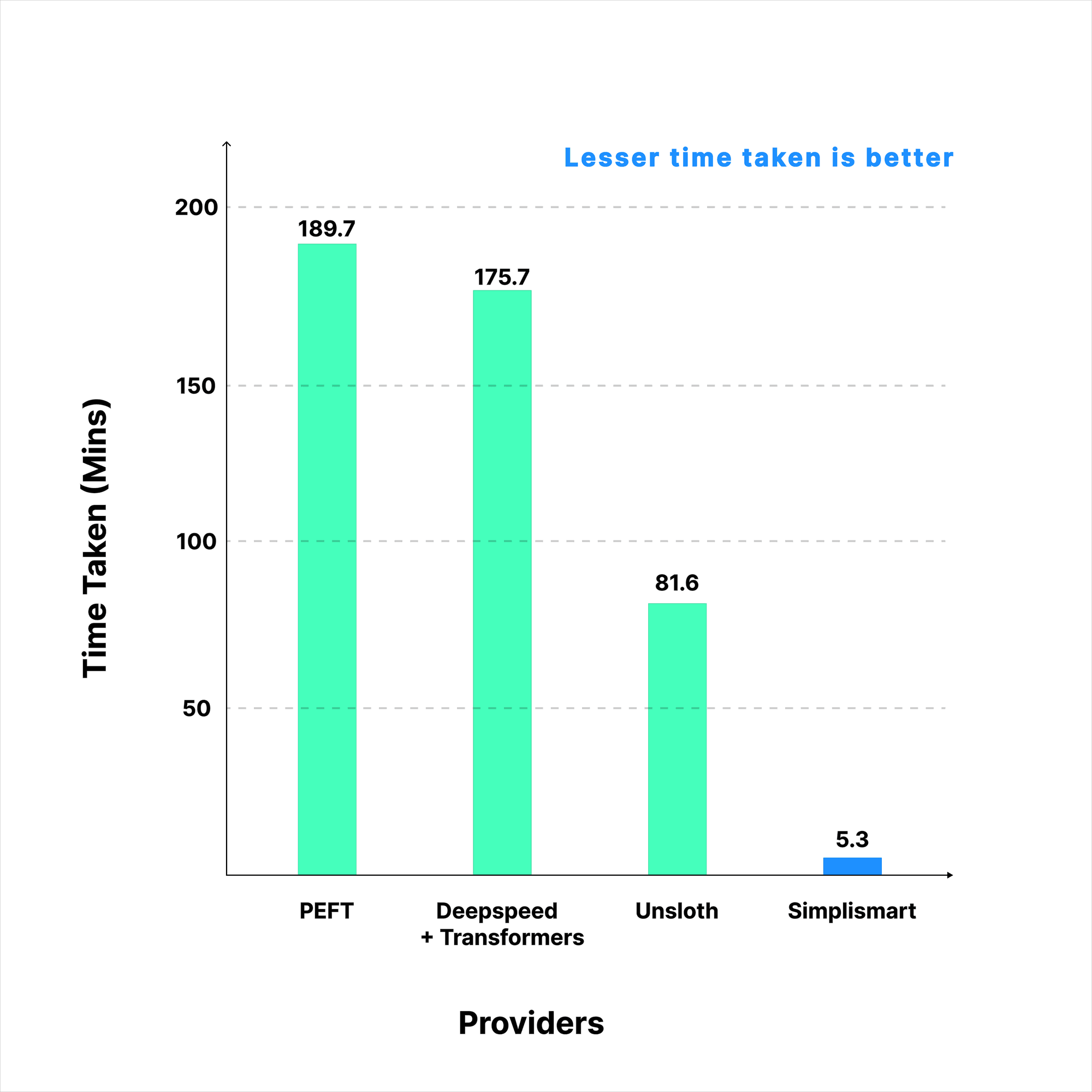
This translates to:
- 15.4× average speed-up vs. Unsloth
- 35.7× speed-up vs. PEFT
- 33x speed-up vs. Deepseed + Transformers
Most importantly, these gains come without any drop in quality. Downstream metrics such as Radiology-mini ROUGE and perplexity remained statistically unchanged.
Result: Lowest per-job cost as well as shortest training time than any provider out there, yes you read it right :)
Final Thoughts
Fine-tuning is rapidly becoming the default path for enterprise teams needing model alignment, structured outputs, and domain adaptation.
With 75%+ of enterprises already integrating LLMs into their AI strategies in 2025 (Amplework), the demand for efficient, reliable fine-tuning will only accelerate.
While frameworks like PEFT, Transformers, DeepSpeed, and Unsloth each solve parts of the fine-tuning puzzle, they leave gaps around scalability, orchestration, and production readiness. Simplismart is designed to close those gaps delivering the fastest, most flexible, and most cost-effective fine-tuning at true enterprise scale.
Contact Us to start improving your model outputs.



