Simplismart Blog
Expert guides and engineering deep dives to help you ship faster, scale easier, and learn along the way.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.

News
Model Performance
June 4, 2026
•
6 mins
NVIDIA Nemotron 3 Ultra Now Available on Simplismart: Tailored Inference for Agentic AI

• 2 others
Model Performance
May 12, 2026
•
5 min
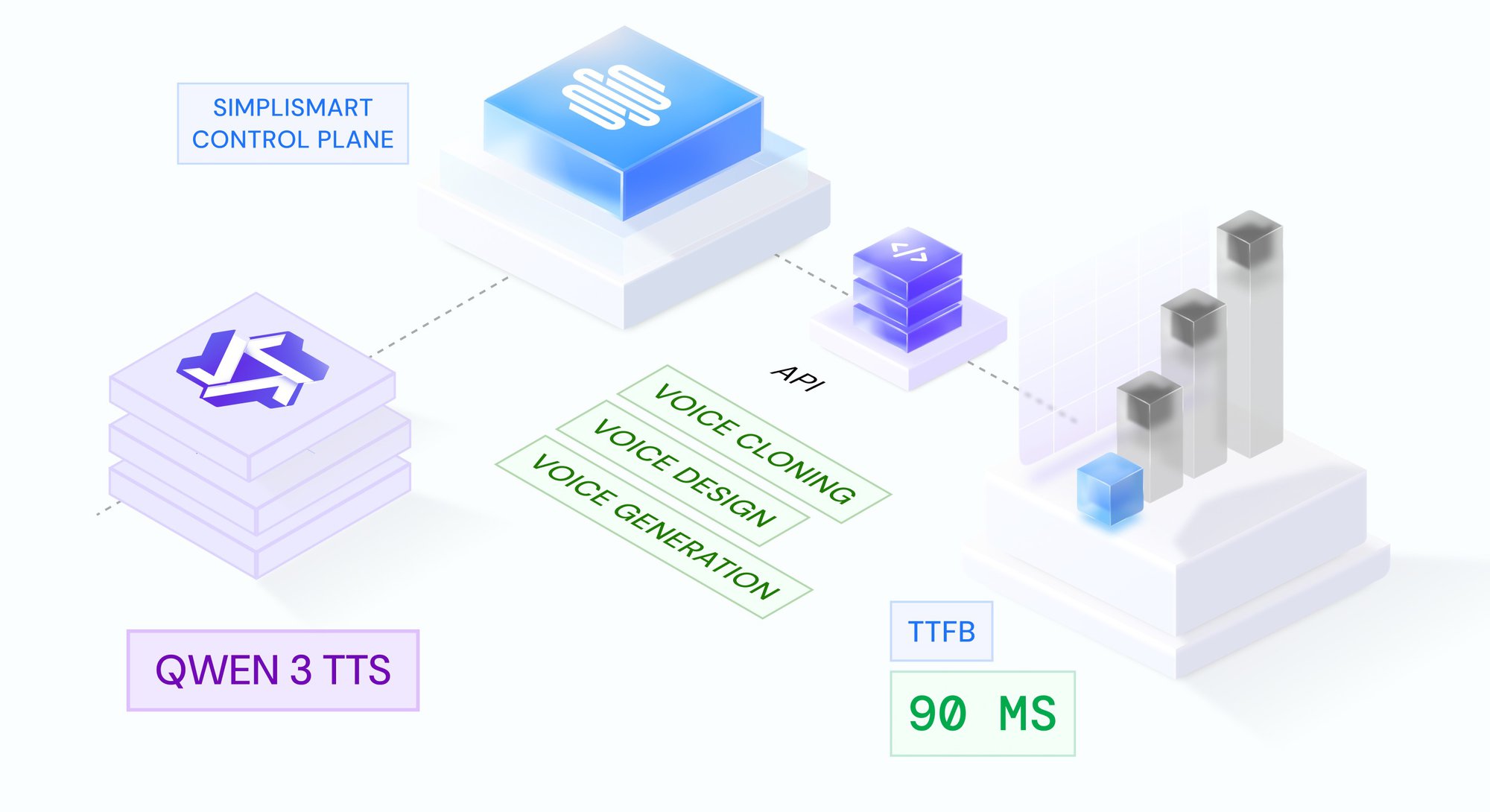
Qwen 3 TTS on Simplismart: Production Voice Synthesis at 90ms TTFB

• 1 other

Model Performance
April 20, 2026
•
5 min
Gemma 4 Deployment on Simplismart: Omni-Modal Open-Weight Inference That Scales in Production
• 1 other
Infrastructure
April 7, 2026
•
8 mins
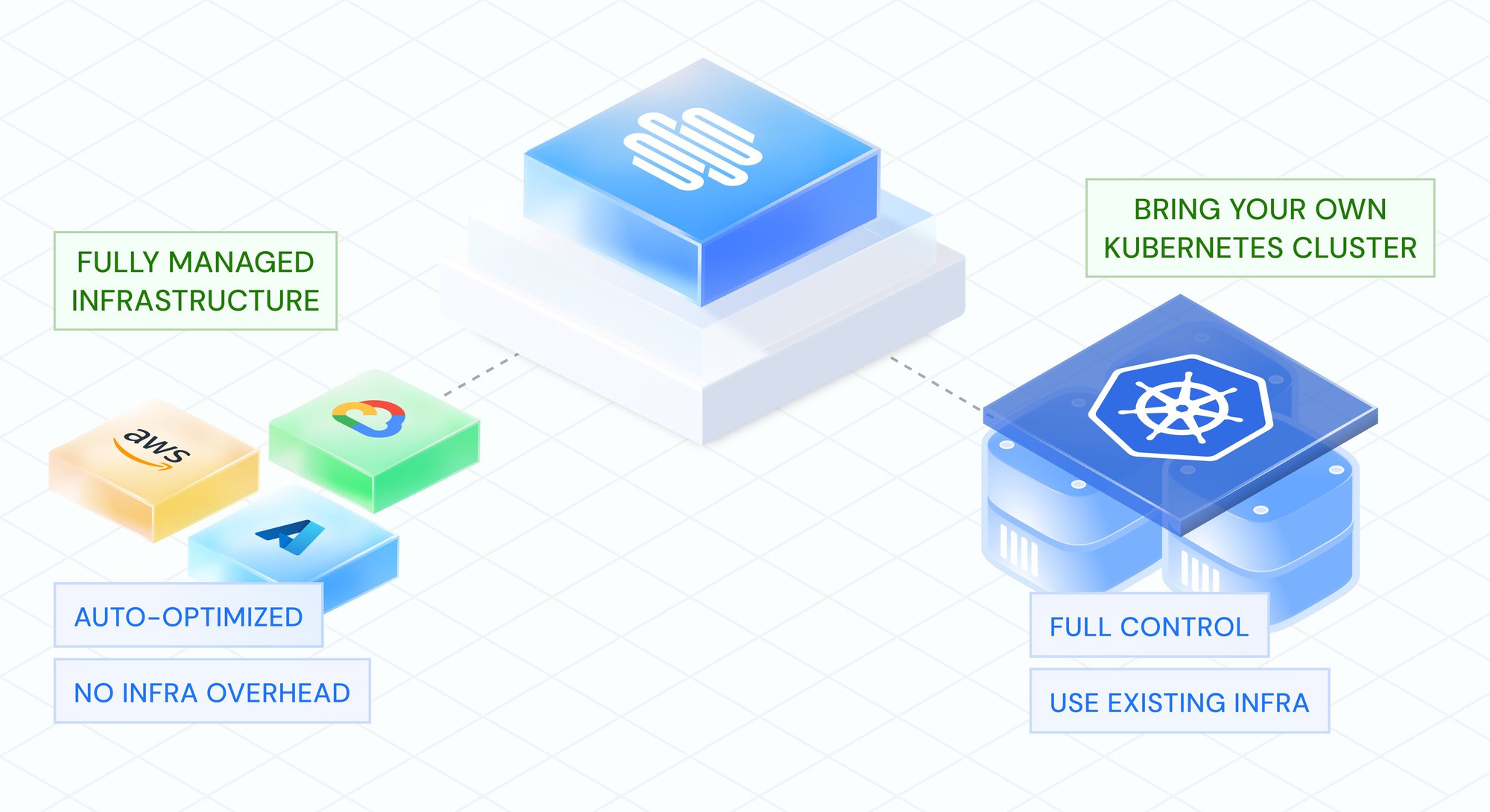
Running GenAI in Your Cloud: The Infrastructure Layer You Don’t Have to Build
• 2 others
Model Performance
March 31, 2026
•
5 min
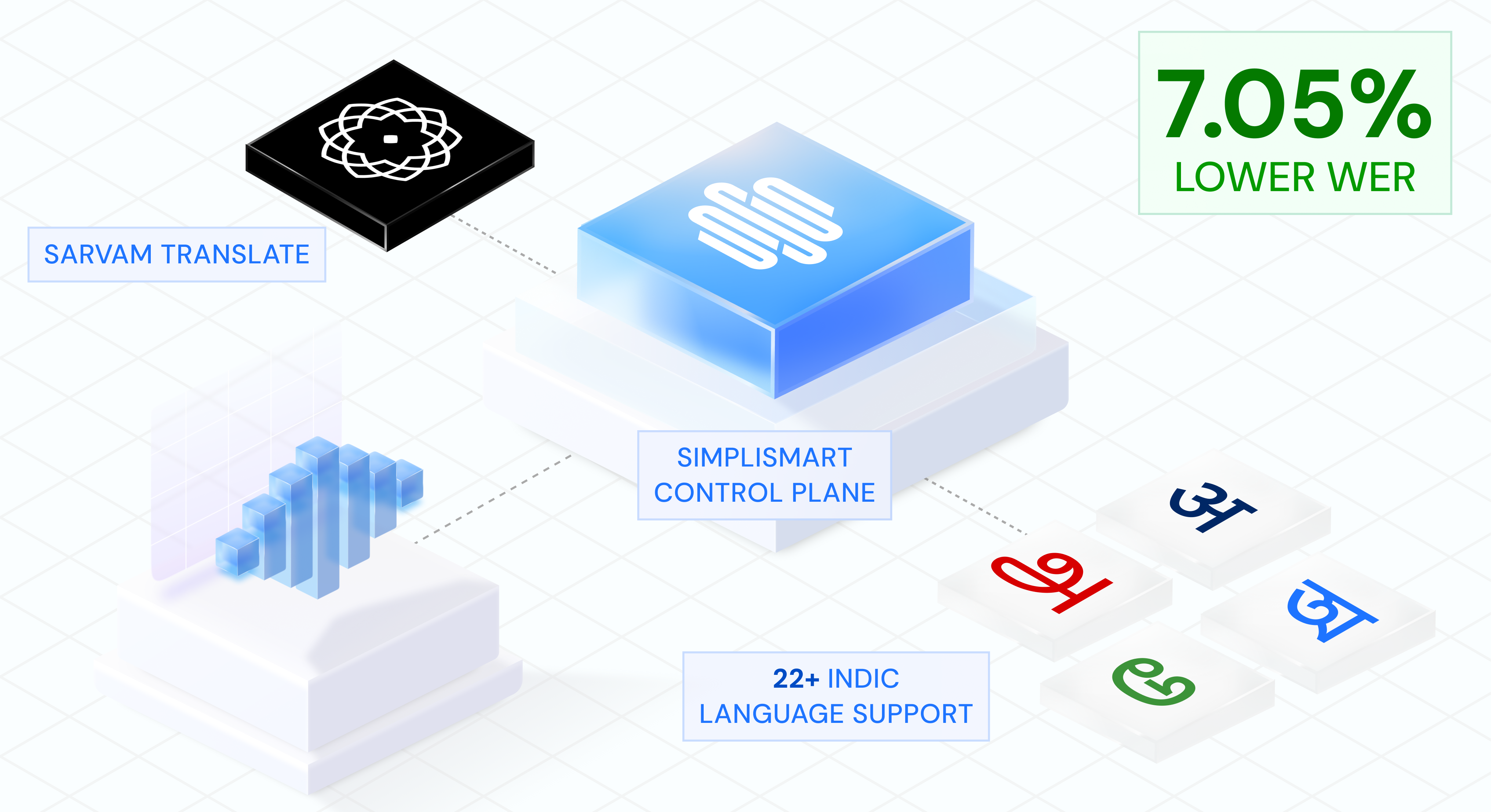
How Open Source Indic AI Models Are Beating SOTA Models
• 1 other
Model Performance
March 24, 2026
•
5 mins
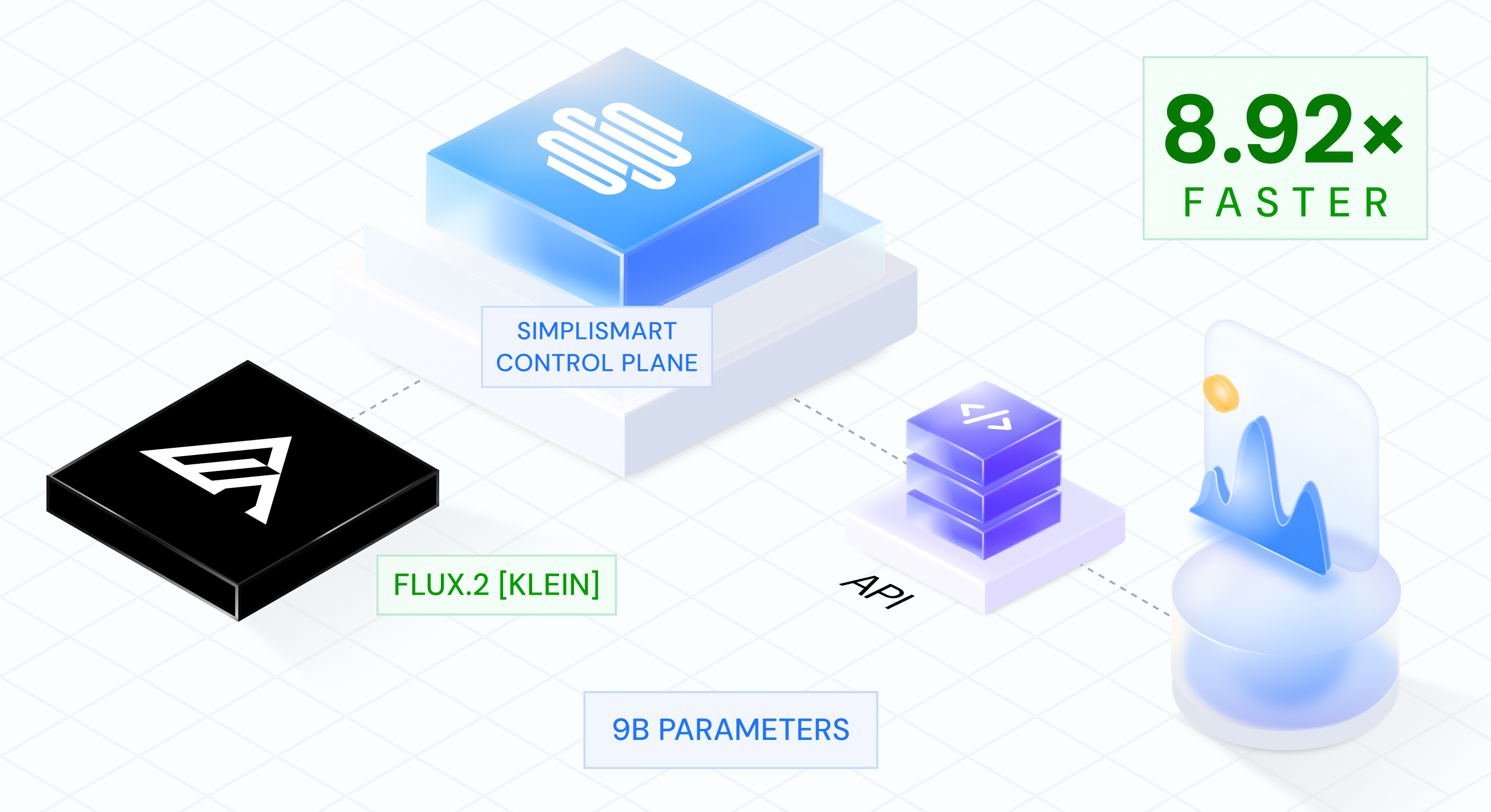
FLUX 2 Klein on Simplismart: Faster AI Image Generation with the Flux 2 Klein API
• 1 other

News
February 23, 2026
•
5 mins
Announcement: Simplismart Launches Advanced AI Inference Platform for Cloud Providers on NVIDIA Infrastructure

• 1 other
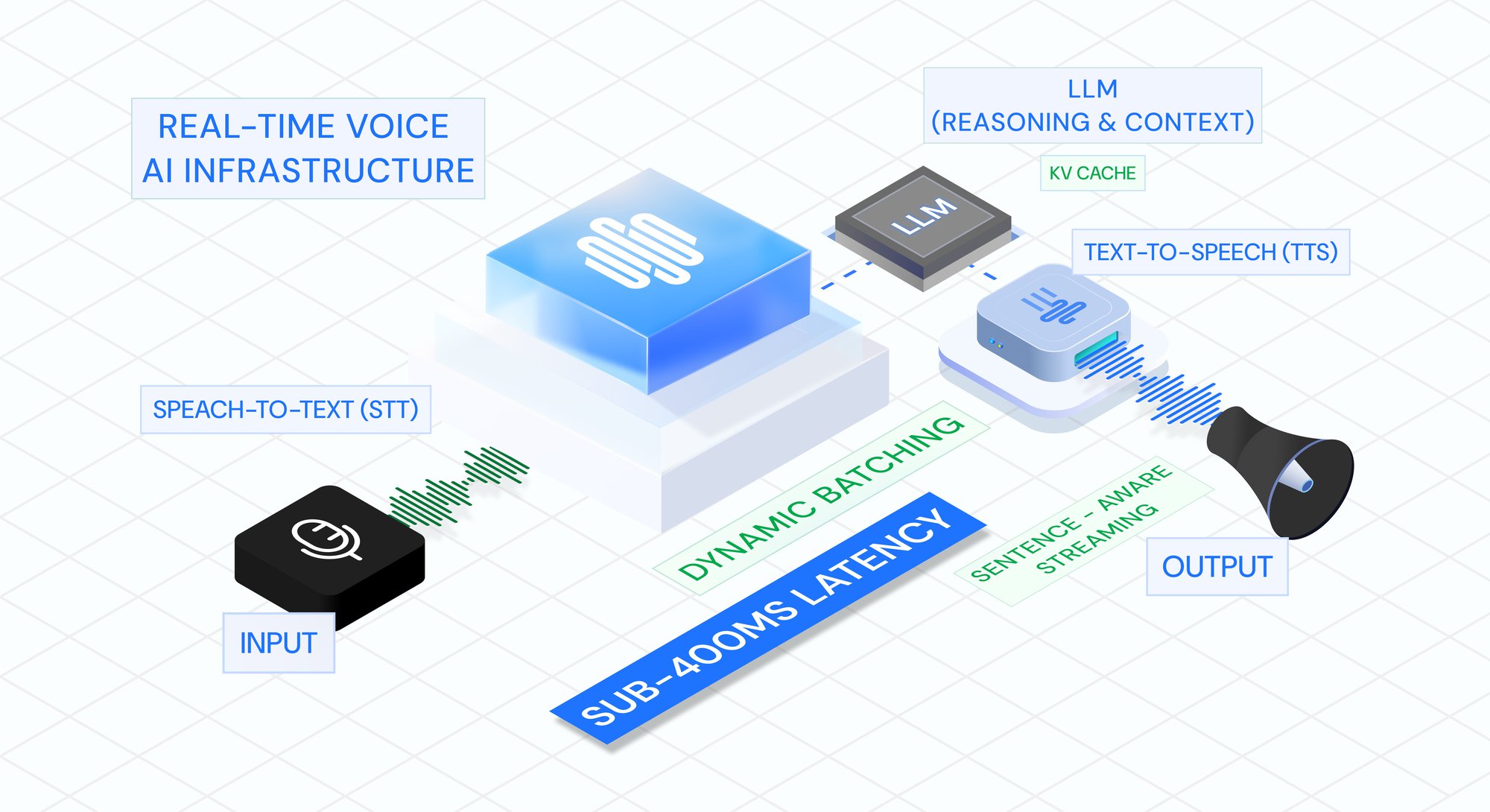
Infrastructure
January 29, 2026
•
10 mins
Building Real-Time Voice AI: Inside the Infrastructure That Achieves Sub-400ms Human-Like Conversations
• 2 others
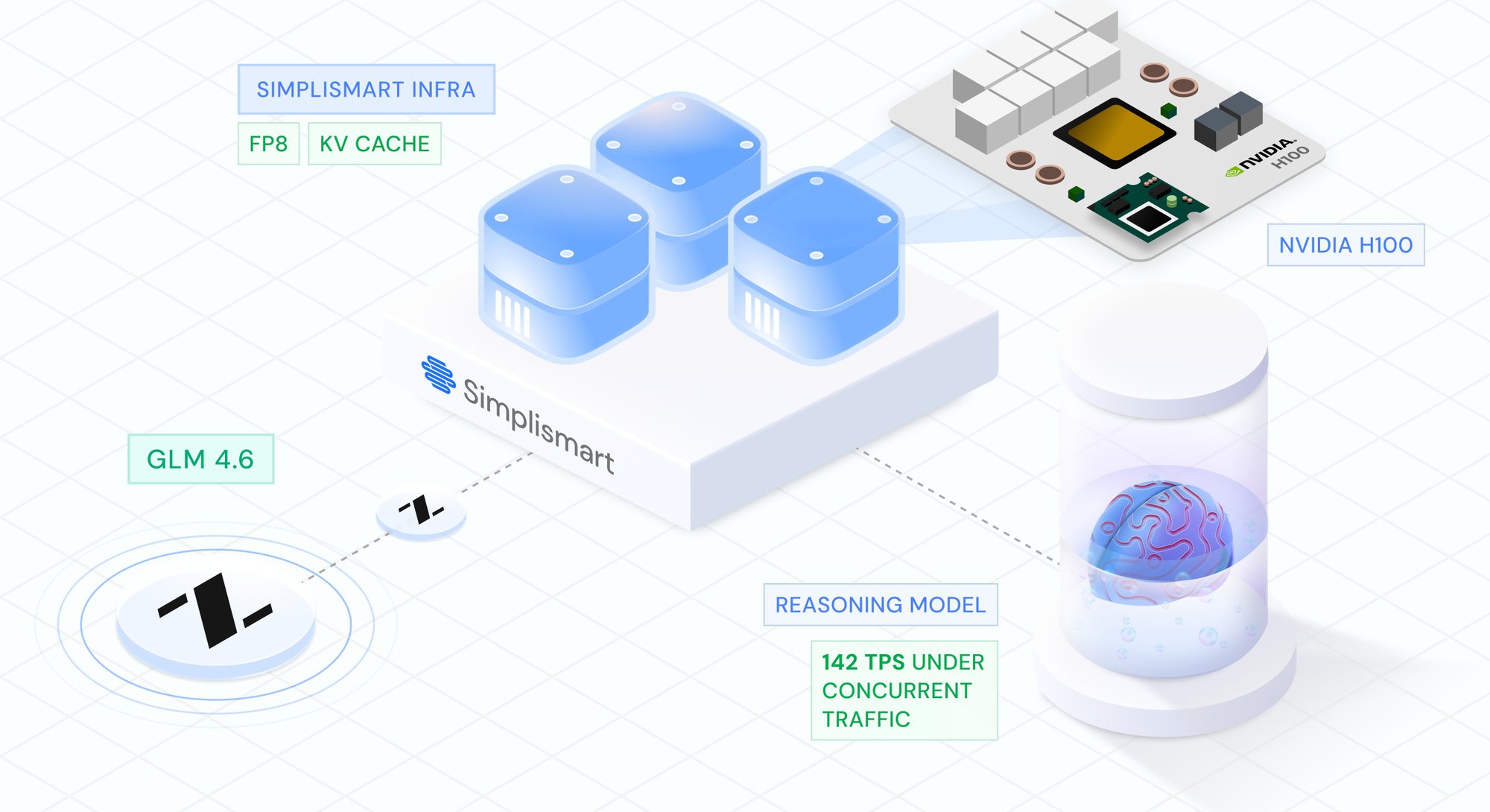
Model Performance
January 19, 2026
•
5 mins
Optimizing GLM-4.6 Inference on H100 GPUs: FP8, MTP, and High-Throughput Serving
• 1 other




© 2026 Verute Technologies Private Limited