



As organizations race to operationalize AI, one question continues to dominate every infrastructure discussion:
Where should our AI live, in the cloud or on-premises?
The truth is, the future isn’t cloud-only or datacenter-only, it’s hybrid AI.
Cloud offers unmatched elasticity and speed of experimentation, while on-prem delivers superior performance, data security, and predictable scaling. Together, they form a balanced foundation where workloads can fluidly shift between environments based on latency, compliance, and cost priorities.
At Simplismart, we’ve built a platform that brings cloud-like speed and automation to on-prem AI infrastructure, helping enterprises deploy, optimize, and scale ML workloads across physical clusters with ease. This guide explores what makes on-prem MLOps unique, where teams struggle, and how Simplismart simplifies the journey to enable a hybrid AI future.
On-Prem MLOps: Advantages and Challenges Across the Six Pillars
To evaluate on-prem MLOps deployments systematically, we can borrow inspiration from the AWS Well-Architected Framework, a proven model for assessing cloud and infrastructure maturity across six key pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability. Applying these same principles to on-prem AI environments provides a balanced view of their strengths and trade-offs.
1. Operational Excellence
Advantage:
- On-prem deployments give ML teams complete operational control from scheduling training jobs to optimizing inference pipelines.
Teams gain full visibility and traceability into what’s running where, down to individual GPU utilization. This transparency makes troubleshooting and workload optimization significantly faster and more predictable.
Challenge:
- Running and monitoring distributed ML systems on-prem requires mature DevOps/MLOps processes. Without automation for configuration management, updates, and observability, teams risk operational bottlenecks and human error.
2. Security
Advantage:
- In shared datacenters, deploying dedicated GPUs for sensitive workloads requires strict isolation, restricted access, and even visual shielding of hardware to meet compliance mandates. With on-prem deployments, enterprises retain full physical custody of their GPUs, ensuring complete data sovereignty and hardware-level security without any third-party dependency.
- Industries such as BFSI, Healthcare & Life Sciences, Government & Defense, and Telecom are bound by PCI-DSS, HIPAA, GDPR, and other applicable regulations. These frameworks mandate data sovereignty and to ensure full control over data residency, governance, and auditability, many enterprises opt for on-prem AI infrastructure.
Challenge:
- Physical isolation increases responsibility. Enterprises must manually maintain firewall policies, access control lists, and compliance audit trails. Continuous alignment with applicable regulations can become tedious without centralized automation.
3. Reliability
Advantage:
- Cloud environments often come with built-in failover mechanisms that make them inherently reliable. However, with the right architecture - including redundant nodes, local failover systems, and predictable network paths, on-prem environments can match that reliability, ensuring consistent uptime and resilience without internet dependency.
Challenge:
- Recovery from hardware failure or misconfiguration is manual and time-sensitive. Enterprises need well-defined runbooks, backup strategies, and monitoring systems to detect and remediate issues swiftly.
- Effective recovery also depends on having an experienced infrastructure team capable of rapid diagnosis, hardware replacement, and system restoration to minimize downtime.
4. Performance Efficiency
Advantage:
- Direct access to GPUs and CPUs minimizes virtualization overhead, delivering ultra-low latency and high throughput for production inference ensuring maximum performance
- Optimized resource scheduling ensures that compute-intensive workloads (training or fine-tuning) fully utilize hardware without throttling or contention.
Challenge:
- Scaling requires physical provisioning: adding racks, reconfiguring networks, and managing GPU placement. Unlike the cloud, scaling beyond already procured GPUs demands new hardware procurement and setup, introducing downtime and delays in the expansion cycle.
5. Cost Optimization
Advantage:
- Once deployed, on-prem clusters offer predictable, transparent operating costs with no surprise egress fees, no per-token charges, and no unpredictable cloud bills that spike with usage. For teams running steady, high-volume workloads, the total cost of ownership (TCO) is often significantly lower than cloud alternatives.
Challenge:
- Building an on-prem GPU cluster demands major CAPEX including servers (NVIDIA/AMD GPUs), high-speed storage (WekaFS), and networking (Palo Alto networks). Procurement delays and hardware refresh cycles affect ROI unless utilization remains high.
6. Sustainability
Advantage:
- On-prem environments offer full visibility and control over power usage, cooling systems, and hardware lifecycle management, enabling organizations to design for energy efficiency and carbon accountability. By choosing renewable energy sources, optimizing workload scheduling, and extending GPU lifecycles, enterprises can build verifiable ESG-aligned sustainability programs with transparent reporting.
Challenge:
- Maintaining energy efficiency and modernizing infrastructure as new GPU architectures emerge (e.g., Hopper, Blackwell) requires proactive investment and recycling strategies.
The On-Prem Deployment Lifecycle
Deploying AI infrastructure on-prem requires precise coordination across hardware, networking, and software layers. The process typically moves through a well-defined lifecycle from initial planning and procurement to deployment, optimization, and ongoing operations. The following table outlines each phase, key tasks, and common tools used in enterprise-grade on-prem MLOps environments.
For detailed guidance, Oracle’s bare metal GPU cluster deployment guide is an excellent technical reference.
Top Mistakes Teams Make with On-Prem MLOps and How Simplismart Avoids Them
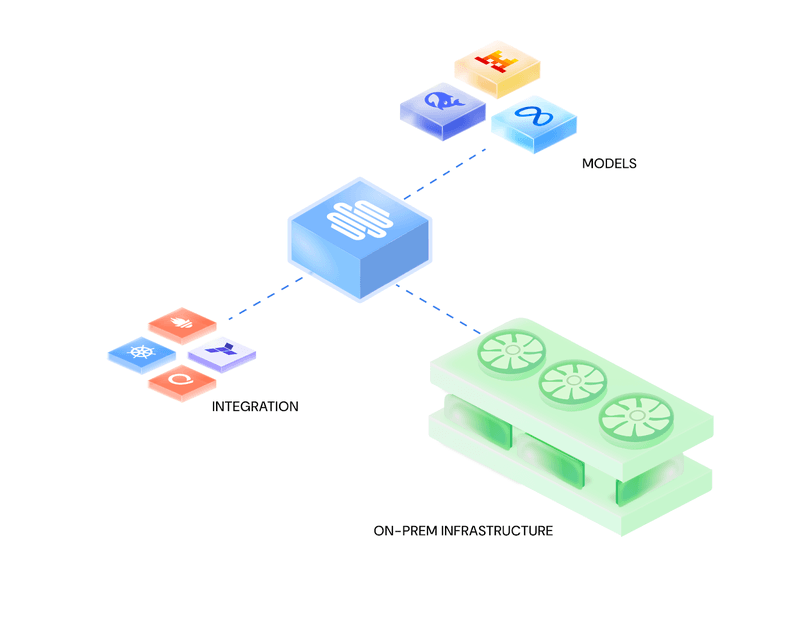
In a perfect setup, on-prem infrastructure, ML models, and MLOps integrations flow in harmony with unified orchestration, seamless connectivity, and zero manual overhead. In reality, most teams struggle to reach this state due to fragmented tooling, manual setup, and compliance complexity. The following section breaks down the most common pitfalls and how Simplismart helps teams avoid them.
Manual Setup Slows Everything Down
Many teams underestimate the complexity of setting up on-prem MLOps environments. Installing drivers, configuring Kubernetes clusters, and tuning GPUs take weeks delaying go-live and introducing inconsistencies across clusters.
Simplismart’s Fix:
- Pre-configured templates for OS, Kubernetes, and ML frameworks (PyTorch, TensorFlow, Triton) accelerate repeatable setup.
- Config-as-Code automation to streamline setup across drivers, networking, and storage.
- Zero-touch GPU configuration that auto-detects hardware and tunes drivers and operators for optimal on-prem performance.
Performance Bottlenecks at Scale
Scaling inference or training workloads in on-prem MLOps setups often leads to throughput drops or latency spikes. Hardware gets underutilized, and debugging cross-node inefficiencies becomes a constant pain.
Simplismart’s Fix:
- Unified serving layer for LLMs, diffusion, and speech models with ultra low latency.
- Optimized application-level backend architecture that leverages parallelization, chunking, optimized I/O, and asynchronous pipeline execution to maximize GPU utilization and throughput. For example - on Simplismart’s customized backend, Whisper-v3 Turbo achieved ~1300× real-time throughput (RTF) on H100s compared to the typical ~60× RTF baseline. Read more about it here
- Smart load balancing that intelligently routes workloads across heterogeneous GPU clusters using strategies like cache-aware routing, latency-aware routing, prefix-aware routing, and geo-location routing among others to maximize performance and utilization.
Compliance Is an Afterthought
In regulated industries, on-prem MLOps demand strict adherence to standards like SOC 2, HIPAA, or GDPR. Yet, many teams bolt on security later creating compliance gaps and audit risks.
Simplismart’s Fix:
- Deploy in isolated environments including hybrid VPC and air-gapped environments with zero data exposure.
- Automated compliance validation for SOC 2, HIPAA, and GDPR frameworks.
- Policy-based access control and secure artifact management baked into Simplismart’s control plane.
Opaque Costs and Vendor Lock-In
Cloud-style per-token or per-request pricing models make cost tracking unpredictable and unsustainable at scale.
Simplismart’s Fix:
- Single-license model covering all models, users, and workflows with no hidden fees.
- 99.9% uptime SLA and integrated observability ensure reliability and transparency.
- Unified billing dashboard for complete visibility into compute utilization and cost efficiency.
Limited Visibility Across the ML Lifecycle
Without proper observability, teams struggle to trace performance issues, monitor GPU usage, or detect model drift leading to reactive firefighting instead of proactive performance. management.
Simplismart’s Fix:
- End-to-end observability across applications including training, deployment, and inference.
- Real-time dashboards built on Grafana for latency, throughput, TTFT, RTFX and GPU health.
- Model and Infra level Predictive alerting including hardware failures and scaling thresholds to ensure seamless uptime.
The Bottom Line
Simplismart transforms on-prem MLOps from a complex, error-prone operation into a cloud-like, automated experience by accelerating deployment, improving performance, and ensuring compliance at enterprise scale.
What You Need Before Simplismart Supercharges Your On-Prem MLOps
Before Simplismart steps in, certain foundations must be in place to unlock full value from your on-prem deployment:
- GPU Infrastructure: Your physical datacenter and GPU clusters should already be provisioned, or you should be in the process of planning or acquiring them as part of your on-prem buildout.
- Networking Configuration: A basic network setup must be in place, with proper routing and connectivity between nodes. During setup, there should also be provision for external internet access to enable dependency downloads and license verifications.
- (Optional) Kubernetes Setup: Kubernetes can either be pre-configured by your internal team or provisioned via Simplismart’s assisted deployment service for faster, production-grade readiness.
Once these basics are in place, Simplismart handles everything else from automating deployment and optimizing inference to managing training, compliance, and observability.
Closing Thoughts
With Simplismart, enterprises gain the speed and automation of cloud-native MLOps on their own hardware.
We simplify on-prem deployment, enforce compliance automatically, and ensure every inference runs at peak performance.
Ready to transform your on-prem infrastructure into a high-performance MLOps engine?
Get your customized on-prem deployment blueprint or request a live demo →



