

Speech-to-text models like Whisper v3 Large has become essential for modern applications, from transcription services and voice assistants to accessibility tools. If you want to deploy Whisper for your own applications, you've likely explored commercial solutions and encountered some painful tradeoffs.
- Cloud API costs add up fast: OpenAI's Whisper API charges $0.006 per minute. At scale, transcribing 100,000 hours annually costs $36,000.
- Latency can be unpredictable: Network calls to cloud services introduce variable delays, making real-time applications challenging.
- Privacy concerns are real: Sending sensitive audio data to third-party servers isn't acceptable for healthcare, legal, or enterprise applications.
- Vendor lock-in limits flexibility: You're dependent on pricing, availability, and feature roadmaps you don't control.
The good news? OpenAI's Whisper models are open source. Moreover, with the right optimization stack, you can deploy them yourself with performance that rivals or exceeds commercial offerings.
In this tutorial, you'll learn how to deploy Whisper v3 Large with a production-ready setup that achieves sub-second latency on GPU. Furthermore, we'll use Faster-Whisper (up to 4x faster) and Vox-Box (an OpenAI-compatible API server for TTS and STT tasks) to create a self-hosted speech-to-text service.
By the end, you'll have:
- A working Whisper v3 deployment with OpenAI compatible API endpoint
- Performance comparison between CPU vs GPU modes
- Understanding of when to scale beyond DIY solutions
Let's dive in!
Understanding the Stack: What You Need to Deploy Whisper v3 Large
Before we start deploying, let's understand what makes this stack powerful. Additionally, we'll explore why each component matters for a successful deployment.
Why Whisper v3 Large?
OpenAI's Whisper family of models revolutionized speech recognition by combining massive scale training with a new architecture focusing on Automatic Speech Recognition (ASR) and speech translation. Specifically, Whisper v3 Large Turbo offers:
- Exceptional multilingual support: 99 languages with strong performance across diverse accents and dialects
- Superior accuracy on challenging audio: Technical vocabulary, medical terms, proper nouns, and domain-specific language
- Robust noise handling: Trained on a total of 5 million hours of diverse labeled audio, including noisy real-world conditions
- Open source and self-hostable: Complete pre-trained model weights available under Apache 2 permissive license.
- Active community: Extensive tooling, optimizations, and pre-trained variants
For this tutorial, we're using Whisper Large v3 Turbo instead of Whisper Large v3, as the Turbo model delivers similar accuracy to Whisper large v3's at significantly higher speeds.
The Performance Problem with Vanilla Whisper
While Whisper's accuracy is impressive, the original OpenAI implementation has significant performance limitations:
- Memory hungry: Loads full precision models, consuming 4GB+ vRAM for Large models
- Not optimized for production: Single-threaded, no batching, inefficient tensor operations
- No API server: Whisper is supported in the HuggingFace Transformers. However, you'd need to build your own API wrapper
This is fine for research or occasional transcription. However, it's not viable for production applications. Specifically, it struggles when handling hundreds of requests per minute.
Faster-Whisper: The Key to Deploy Whisper Efficiently
Faster-Whisper is a complete reimplementation of Whisper using CTranslate2, a high-performance inference engine for Transformer models.
What makes it faster?
- Quantization: Converts FP32 weights to INT8 or FP16 with minimal accuracy loss, reducing model size by 75%. Read more.
- Memory efficiency: Dynamic memory allocation based on the usage and while maintaining the performance using the caching allocators on both CPU and GPU.
- Layer fusion: Combines multiple operations into single GPU kernels
Results: Up to 4x faster than the original implementation while using less memory, with the same accuracy.
The efficiency can be further improved with 8-bit quantization on both CPU and GPU. As a result, it's practical to deploy Whisper even on modest hardware.
Vox-Box: The Missing API Layer
Having an optimized inference engine is great, but production deployments need more:
- HTTP API for easy integration
- Health checks and monitoring
Vox-Box fills this gap by providing an OpenAI-compatible API server specifically designed for text-to-speech and speech-to-text models. It wraps Faster-Whisper with production-ready features:
- Drop-in replacement: Uses the same API format as OpenAI's /v1/audio/transcriptions endpoint
- Simple deployment: Single command to start the server
- Flexible configuration: CPU or GPU mode, multiple model support, custom parameters
- Built for production: Request logging, error handling, graceful shutdown
The combination of Faster-Whisper + Vox-Box gives you a complete, production-ready stack without building infrastructure from scratch.
Prerequisites
Before we begin, ensure you have the following:
System Requirements
Minimum specifications
- Ubuntu 20.04/22.04 LTS (or similar Linux distribution)
- 8GB RAM minimum (16GB recommended)
- 20GB free disk space for model storage
- Python 3.10 or 3.11 (Python 3.12 has compatibility issues with some dependencies)
For GPU acceleration (highly recommended):
- NVIDIA GPU with 6GB+ VRAM (Tested on H100)
- NVIDIA GPU driver
- cuBLAS for CUDA 12
- cuDNN 9 for CUDA 12
Software Dependencies
Required:
- Python 3.10 (recommended) or 3.11
- pip and virtualenv
- curl (for testing the API)
GPU Setup (If Applicable)
If you're using GPU acceleration, verify your CUDA installation:
Check NVIDIA driver
nvidia-smi
Check CUDA version
nvcc --version
If you need to install CUDA and cuDNN, follow NVIDIA's official guides:
With prerequisites confirmed, let's set up our environment.
Step 1: Environment Setup
We'll start by creating a clean Python environment and installing Vox-Box.
Create a Virtual Environment
Using a virtual environment keeps dependencies isolated and prevents conflicts:
Create a directory for the project
mkdir whisper
cd whisper
Create virtual environment with Python 3.10
python3.10 -m venv whisper-env
Activate the environment
source whisper-env/bin/activate
Verify Python version
python --version
Note for MacOS users: Use python3 instead of python3.10 if you installed Python via Homebrew.
Install Vox-Box
With the virtual environment activated, install Vox-Box:
Upgrade pip first
pip install --upgrade pip
Install vox-box
pip install vox-box
Verify installation
vox-box --version
If you encounter any errors during installation, ensure you have build essentials:
For Ubuntu/Debian
sudo apt-get update
sudo apt-get install -y build-essential python3-dev
Step 2: Understanding the Model
Before deploying, let's understand the specific model we'll use.
The Faster-Whisper Large v3 Turbo Model
We're using a pre-converted CTranslate2 model hosted on Hugging Face, as it works perfectly with the Faster-Whisper and Vox-Box:
Model: deepdml/faster-whisper-large-v3-turbo-ct2
Key specifications:
- Model Size: ~ 1.62GB
- Format: CTranslate2 (optimized for inference)
- Quantization: FP16 (balances speed and accuracy)
- Accuracy: Similar accuracy of original Whisper Large v3 quality
Alternative Models
You can use any of the other whisper implementations by changing the --huggingface-repo-id parameter in the next steps. You can checkout the other supported models on the Vox-Box repo.
Step 3: Deploy Whisper on CPU
Let's start with a CPU deployment to understand the basics. When you deploy Whisper on CPU, this approach is ideal for:
- Development and testing
- Low-volume production workloads (<100 requests/hour)
- Cost-sensitive deployments where GPU costs aren't justified
- Privacy-critical applications on edge devices without GPUs
Launch the Server
Run this command to start Vox-Box in CPU mode:
vox-box start \
--huggingface-repo-id deepdml/faster-whisper-large-v3-turbo-ct2 \
--data-dir ./cache/data-dir \
--host 0.0.0.0 \
--port 8000
Understanding the parameters:
- --huggingface-repo-id: The Hugging Face model repository to use
- --data-dir: Local directory where models are cached (prevents re-downloading)
- --host 0.0.0.0: Listen on all network interfaces (allows external access)
- --port 8000: The port where the API server will listen
First startup takes 2-3 minutes as it downloads the model from Hugging Face. Subsequent starts are instant as the model is cached locally.
You should see output like:
2025-10-06T11:41:17+00:00 - vox_box.cmd.start - INFO - Starting with arguments: [('debug', None), ('host', '0.0.0.0'), ('port', 8000), ('model', None), ('device', 'cuda:0'), ('huggingface_repo_id', 'deepdml/faster-whisper-large-v3-turbo-ct2'), ('model_scope_model_id', None), ('data_dir', './cache/data-dir'), ('func', <function run at 0x7f70745a7490>)]
2025-10-06T11:41:17+00:00 - vox_box.server.model - INFO - Estimating model
Fetching 1 files: 100%|████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4.28it/s]
Fetching 1 files: 100%|████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4.46it/s]
2025-10-06T11:41:17+00:00 - vox_box.server.model - INFO - Finished estimating model
2025-10-06T11:41:17+00:00 - vox_box.server.model - INFO - Downloading model
Fetching 7 files: 100%|█████████████████████████████████████████████████████████████████| 7/7 [00:00<00:00, 10072.09it/s]
2025-10-06T11:41:18+00:00 - vox_box.server.model - INFO - Loading model
2025-10-06T11:41:21+00:00 - vox_box.server.server - INFO - Starting Vox Box server.
2025-10-06T11:41:21+00:00 - vox_box.server.server - INFO - Serving on 0.0.0.0:8000.
The server is now ready to accept requests!
Step 4: Making Your First Transcription
With the server running, let's test it with a real audio file.
Prepare a Test Audio File
You can use any audio file you have, or download a sample:
Download JFK's famous speech (11 seconds)
wget https://github.com/ggerganov/whisper.cpp/raw/master/samples/jfk.wav
Send a Transcription Request
Vox-Box implements OpenAI’s audio transcriptions API endpoint, so if you've used OpenAI's API before, this example code will feel familiar:
curl -X POST http://localhost:8000/v1/audio/transcriptions \
-H "Authorization: Bearer optional-token" \
-F "file=@jfk.wav" \
-F "model=faster-whisper-large-v3-turbo-ct2"
Parameter explanation:
- Authorization: Bearer optional-token: API keys for the endpoint (optional in this basic setup)
- file=@jfk.wav: The audio file to transcribe (@ indicates file upload)
- model=...: The model identifier (must match the repo ID)
Expected Response
After a couple of seconds, you'll receive a JSON response:
{"text":"And so, my fellow Americans, ask not what your country can do for you, ask what you can do for your country."}
In our testing, it took 9-10 seconds to process 45 seconds long audio.
Step 5: Deploy Whisper on GPU
GPU deployment dramatically improves performance, making real-time and high-volume applications practical.
Launch with GPU Acceleration
Stop the CPU server (Ctrl+C) and restart with GPU support:
vox-box start \
--huggingface-repo-id deepdml/faster-whisper-large-v3-turbo-ct2 \
--data-dir ./cache/data-dir \
--host 0.0.0.0 \
--port 8000 \
--device cuda:0
The key difference is --device cuda:0, which tells Vox-Box to use the first CUDA-enabled GPU.
Multi-GPU setups: If you have multiple GPUs, specify them individually:
- --device cuda:0 for first GPU
- --device cuda:1 for second GPU
- Run separate instances on different ports for parallel processing
Startup is faster this time since the model is already cached.
Test GPU Performance
Use the same cURL command as before:
curl -X POST http://localhost:8000/v1/audio/transcriptions \
-H "Authorization: Bearer optional-token" \
-F "file=@jfk.wav" \
-F "model=faster-whisper-large-v3-turbo-ct2"
This time, you'll notice the response comes back much faster!
Note: First request might take a little longer due to the cold start. However, the subsequent requests should get a faster response.
In our testing, it took 1-1.5 seconds to process 45 seconds long audio.
Step 6: Advanced API Usage
Now that your server is running efficiently, let's explore advanced features of the transcription API.
Additional Parameters
The Vox-Box API supports several optional parameters for different output formats:
curl -X POST http://localhost:8000/v1/audio/transcriptions \
-H "Authorization: Bearer optional-token" \
-F "file=@audio.mp3" \
-F "model=faster-whisper-large-v3-turbo-ct2" \
-F "language=en" \
-F "temperature=0" \
-F "response_format=verbose_json"
Parameter guide:
- language: ISO 639-1 language code (e.g., "en", "es", "fr")
- Speeds up processing by skipping language detection
- Use when you know the audio language in advance
- temperature: Controls randomness
- 0: Deterministic output (recommended for production)
- 0.2-0.8: More creative transcription
- Use 0 for consistent results across runs
- response_format: Output format
- json: Simple text output (default)
- verbose_json: Includes timestamps and confidence scores
- text: Plain text only
- srt: Subtitle format
- vtt: WebVTT format
Simplismart Whisper: Taking It Further
The Faster-Whisper + Vox-Box stack we've built provides excellent performance for most use cases. However, if you're building truly large-scale production systems, you may hit limitations:
- Handling thousands of concurrent requests
- Sub-200ms latency requirements
- Advanced features like speaker diarization
- Enterprise SLA and support guarantees
- Optimized resource utilization at scale
This is where Simplismart Whisper comes in.
What Makes Simplismart Different?
Simplismart has taken Whisper optimization to the next level with optimization techniques:
1. Extreme Performance:
- 1300x real-time factor (vs 30x with standard GPU setup)
- Processes 15 minutes of audio in ~40 seconds
2. Advanced Features:
- Speaker diarization (who spoke when)
- Custom vocabulary and terminology
- Real-time streaming transcription
- Batch processing optimizations
- Fine-tuning support for domain-specific needs
3. Enterprise Support:
- 99.9% uptime SLA
- Custom deployment options (cloud, on-prem, hybrid)
- Compliance certifications (SOC 2, GDPR, HIPAA)
Performance Benchmarks
Here's how different solutions compare on the same audio workload:
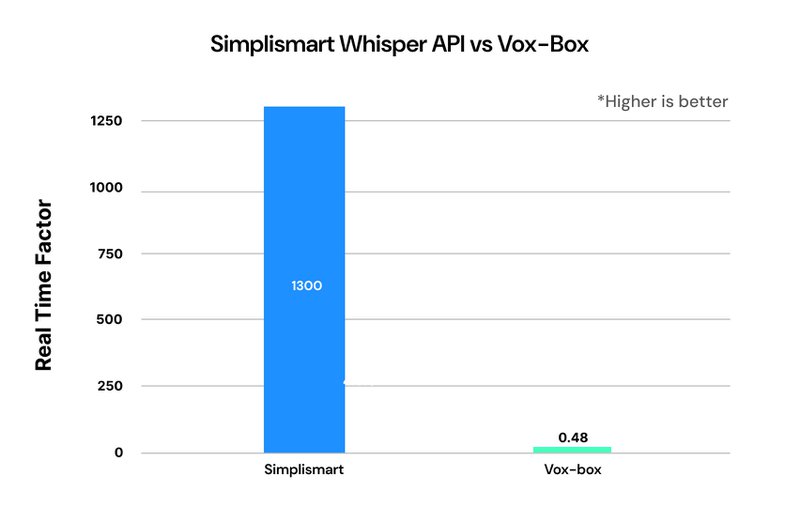
Note: Both of these benchmarks were performed from a remote instance.
When to Consider Simplismart
You should consider Simplismart if:
- Processing a large number of requests per month
- Need sub-300ms latency for real-time applications
- Building multi-tenant SaaS with transcription
- Require enterprise SLA and compliance
- Want to minimize infrastructure management
- Need advanced features beyond basic transcription
Cost Comparison at Scale: Self-deploy whisper vs Simplismart
For a production system processing 10 million minutes/month:
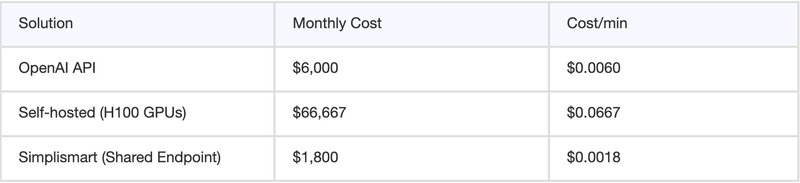
If you want an on-prem or dedicated deployment of Whisper, you can check out this model deployment guide.
Simplismart sits between self-hosted complexity and cloud API costs, offering managed infrastructure with near-self-hosted performance.
Learn More
Read the full benchmark report with detailed methodology and results: Fastest Whisper V3 Turbo: Serving Millions of Requests at 1300x Real-Time
Conclusion
Congratulations! You've successfully deployed a production-ready Whisper v3 Large Turbo speech-to-text pipeline that processes audio 30x faster than real-time on GPU.
What You've Accomplished
✅ Understanding the stack: Learned why Whisper, Faster-Whisper, and Vox-Box work together effectively
✅ CPU and GPU deployment: Set up both modes and understand their tradeoffs
Resources:



