

Meta's Llama 3.1 8B is like a perfect Swiss Army knife of LLMs, powerful enough for real-world applications, yet compact enough to run on a single GPU. But here's the thing: when you deploy Llama models, just loading a model and calling it a day won't cut it in production. You need speed, efficiency, and the ability to handle concurrent requests without breaking a sweat.
vLLM is a high-performance inference engine built specifically for large language models. Think of it as a Formula 1 pit crew when you deploy Llama or any other LLM, implementing cutting-edge techniques like PagedAttention, continuous batching, and hardware-specific optimizations that can dramatically boost performance.
In this comprehensive guide to deploy Llama 3.1 8B, we'll start from zero and build up to a production-ready deployment. We'll explore:
- Set up a basic vLLM deployment and establish baseline metrics
- Apply different optimization techniques (quantization, tensor parallelism, prefix caching, speculative decoding, and more)
- Run benchmarks to measure real performance improvements
- Combine optimizations for specific use cases (low latency vs. high throughput)
- Share battle-tested tips from production deployments
By the end, you'll know exactly which knobs to turn for your specific use case when you deploy Llama 3.1 8B, whether you're building a chatbot that needs lightning-fast responses or a batch processing system that needs maximum throughput.
Let's dive in!
Prerequisites for Deploy Llama 3.1 8B
Before we begin to deploy Llama 3.1 8B, make sure you have:
- An NVIDIA GPU with at least 24GB VRAM - We'll start with the full model (16GB in model weights)
- CUDA 11.8or higher. You can check with
nvcc --version - Python 3.8+ - Python 3.10 recommended
- Basic familiarity with Linux, Python and REST APIs
Don't worry if you don't have a beefy GPU. The optimization techniques we'll cover (especially quantization) can make it possible to deploy Llama on smaller GPUs with ~8GB of VRAM too.
Installing vLLM to Deploy Llama
First, let's set up a clean Python environment. Virtual environments are your friend - they keep dependencies isolated and prevent version conflicts.
Create a virtual environment
python3 -m venv vllm-env
Activate it
source vllm-env/bin/activate
Now install vLLM
Install vLLM with automatic backend detection
pip install vllm --torch-backend=auto
Verify the installation
python -c "import vllm; print(vllm.__version__)"
You should see a version number (like `0.6.0` or higher). If you hit any errors, make sure your CUDA installation is working properly with nvidia-smi.
Note: Since Llama 3.1 8B is a gated model, you need to apply for access on HuggingFace by submitting a form on the model page. Once you’ve got access to the model, you need to set HuggingFace token as an environment variable
export HF_TOKEN="HF_XXXXXXXXXXXXX"
Basic Llama Deployment and Your First Inference
Let's start simple and deploy Llama 3.1 8B for your first inference. Create a file called basic_inference.py:
# basic_inference.py
from vllm import LLM, SamplingParams
import os
# Initialize the model
llm = LLM(
model="meta-llama/Meta-Llama-3.1-8B-Instruct",
trust_remote_code=True
)
# Set up sampling parameters
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512
)
# Test prompt
prompts = [
"Explain what a quantum computer is in simple terms."
]
# Generate
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(f"Prompt: {output.prompt}")
print(f"Generated text: {output.outputs[0].text}")
Run it:
python basic_inference.py
What's happening here?
On the first run, vLLM will:
- Download the model weights (~16GB) from Hugging Face
- Load them into GPU memory
- Initialize the inference engine
- Generate a response
After vLLM's initialization logs, you should see output like:
Prompt: Explain what a quantum computer is in simple terms.
Generated text: A quantum computer is a machine that uses quantum mechanics to process information. Unlike regular computers that use bits (0s and 1s), quantum computers use qubits that can be both 0 and 1 at the same time...
Setting Up a OpenAI API Server
While the Python script is great for testing, when you deploy Llama in production you need an API server that can handle concurrent requests. The good news? vLLM has you covered with an OpenAI-compatible API server out of the box!
Start the server:
vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--trust-remote-code
Parameter breakdown:
- --host 0.0.0.0: : Host IP where the vLLM server is running
- --port 8000: The port to serve on
- --trust-remote-code: Trust the model repository’s custom Python code
You'll see initialization logs, and once you see `Application startup complete`, your server is ready!
Testing Your API
Using cURL
The API follows the OpenAI format, so if you've used OpenAI's API, this will feel familiar:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3.1-8B-Instruct",
"messages": [
{"role": "user", "content": "Explain quantization to me like I'\''m a 10 year old child"}
],
"max_tokens": 100,
"temperature": 0.7
}'
You'll get back a JSON response with the generated text. The response follows the OpenAI format:
{
"id": "chatcmpl-3e14d6c880a74fe1a91ba9d2e217317b",
"object": "chat.completion",
"model": "meta-llama/Meta-Llama-3.1-8B-Instruct",
"choices": [{
"message": {
"role": "assistant",
"content": "Imagine you have a big box of crayons, and you want to draw a picture..."
},
"finish_reason": "length"
}],
"usage": {
"prompt_tokens": 50,
"total_tokens": 100,
"completion_tokens": 50
}
}
Using the OpenAI Python Client
vLLM's API is compatible with the OpenAI Python client, making migration seamless. Create openai_inference.py:
# openai_inference.py
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="dummy" # vLLM doesn't require authentication by default
)
response = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-8B-Instruct",
messages=[{"role": "user", "content": "Explain what machine learning is"}],
max_tokens=100
)
print(response.choices[0].message.content)
Run it:
pip install openai # if you haven't already
python openai_inference.py
You'll get output like:
Machine Learning: An Overview
Machine learning is a subset of artificial intelligence (AI) that enables computers to learn from data and improve their performance on a task without being explicitly programmed. It involves feeding algorithms large amounts of data...
The beauty of this approach is that you can swap between OpenAI's API and your vLLM deployment by simply changing the base_url!
Now you have a working API. But how fast is it really? Let's find out.
Establishing Baseline Performance
Before we optimize our deploy Llama setup, let's establish baseline metrics using vLLM's built-in benchmarking tool. Understanding these numbers will help us measure the impact of each optimization.
Run the benchmark:
vllm bench serve \
--model meta-llama/Meta-Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--random-input-len 1024 \
--random-output-len 512 \
--num-prompts 128 \
--max-concurrency 32
Parameter Breakdown:
- --model: The model to benchmark (Llama 3.1 8B Instruct)
- --host and --port: Server connection details
- --random-input-len 1024: Generate prompts with ~1024 input tokens
- --random-output-len 512: Request ~512 output tokens per prompt
- --num-prompts 128: Total number of prompts to send
- --max-concurrency 32: Maximum concurrent requests
Baseline Results
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 32
Benchmark duration (s): 21.80
Total input tokens: 130803
Total generated tokens: 58268
Request throughput (req/s): 5.87
Output token throughput (tok/s): 2673.16
Total Token throughput (tok/s): 8674.00
---------------Time to First Token----------------
Mean TTFT (ms): 301.70
Median TTFT (ms): 255.08
P99 TTFT (ms): 786.34
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 11.96
Median TPOT (ms): 10.32
P99 TPOT (ms): 81.68
---------------Inter-token Latency----------------
Mean ITL (ms): 10.26
Median ITL (ms): 9.36
P99 ITL (ms): 28.42
==================================================
Understanding the Metrics
Let's break down what these numbers mean:
- TTFT (Time to First Token): How long until the user sees the first response token. Critical for perceived responsiveness. Our baseline: ~301.70ms mean.
- TPOT (Time Per Output Token): Average time between successive tokens generated after the first one (i.e., during the streaming phase). Our baseline: ~11.96ms mean.
- ITL (Inter-Token Latency): Similar to TPOT, it measures the time between each consecutive token. Our baseline: ~10.26ms mean.
- Throughput: Tokens processed per second. Higher is better for batch processing. Our baseline: 8,674 total tokens/s. However, we’re making 32 concurrent requests per second, hence this throughput will be divided by 32, which means per request throughput is 271.0625 tokens/s.
Why These Metrics Matter:
Different applications prioritize different metrics:
- Chatbots/RAG: Low TTFT (users want instant feedback)
- Real-time Streaming: Low ITL/TPOT (smooth token flow)
- Batch Processing: High throughput (process more requests)
- Cost Optimization: Maximum throughput per dollar
Now that we have our baseline, let's start optimizing!
Optimization Techniques
Now that we have our baseline metrics, when we deploy Llama, let's explore different optimization techniques. We'll measure the impact of each to understand its trade-offs.
INT4 Quantization with AWQ
Quantization reduces the numerical precision of model weights, trading a small amount of quality for significant memory savings. Think of it like compressing an image: a 4-bit JPEG uses less space than a 32-bit PNG, but looks nearly identical.
INT4 quantization with AWQ (Activation-aware Weight Quantization) reduces each weight from 16 bits (FP16) to just 4 bits, achieving ~75% memory reduction while maintaining most of the model's capabilities.
Memory Impact:
- Original model (FP16): ~16GB VRAM
- INT4 quantized: ~4GB VRAM
- Benefit: Works on smaller GPUs!
Step 1: Get the quantized model
We'll use a pre-quantized model from Hugging Face: hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4
Step 2: Serve the quantized model
vllm serve hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4 \
--host 0.0.0.0 \
--port 8000 \
--quantization awq_marlin \
--dtype half \
--gpu-memory-utilization 0.9
Parameter breakdown:
- --quantization awq_marlin: Use AWQ with Marlin kernels (fastest INT4 implementation for NVIDIA GPUs)
- --dtype half: Use FP16 for activations (recommended for AWQ)
- --gpu-memory-utilization 0.9: Cap GPU memory at 90% (includes model weights, KV cache, and activations)
Note: Different quantization methods work best with different GPU architectures. See vLLM's quantization docs for compatibility.
Benchmark Results
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 32
Benchmark duration (s): 21.30
Total input tokens: 130803
Total generated tokens: 56053
Request throughput (req/s): 6.01
Output token throughput (tok/s): 2631.50
Total Token throughput (tok/s): 8772.27
---------------Time to First Token----------------
Mean TTFT (ms): 565.22
Median TTFT (ms): 441.94
P99 TTFT (ms): 1564.41
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 11.51
Median TPOT (ms): 10.09
P99 TPOT (ms): 58.03
---------------Inter-token Latency----------------
Mean ITL (ms): 9.91
Median ITL (ms): 7.73
P99 ITL (ms): 53.91
==================================================
Trade-off: The quantized model generates tokens faster once started, but takes longer to produce the first token. This happens because INT4 quantization requires additional dequantization overhead during prefill (processing the input prompt).
When to use INT4 Quantization:
- ✅ Limited VRAM (enables deployment on smaller GPUs)
- ✅ Serving multiple models on one GPU
- ✅ Batch inference where throughput matters more than TTFT
- ✅ Cost optimization (smaller GPUs = lower cost)
- ❌ Avoid for applications requiring ultra-low TTFT
Tensor Parallelism (TP)
Tensor Parallelism (TP) splits the model's weight matrices across multiple GPUs. Each GPU computes a portion of the matrix multiplication in parallel, then the results are combined. This is like having multiple chefs working on different parts of a meal simultaneously when you deploy Llama across multiple devices.
For Llama 3.1 8B, TP is optional (the model fits on one GPU), but it significantly improves performance by:
- Parallel computation: Multiple GPUs compute faster than one
- More KV cache: Distributed memory = larger effective batch sizes
- Lower latency: Faster matrix multiplications
Note: TP is essential for larger models (e.g., Llama 70B, DeepSeek V3) that don't fit in a single GPU's VRAM.
Serve with Tensor Parallelism:
vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 2
The --tensor-parallel-size 2 parameter splits the model across 2 GPUs. You can adjust this based on your available GPUs (common values: 2, 4, 8).
Benchmark Results
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 32
Benchmark duration (s): 15.42
Total input tokens: 130803
Total generated tokens: 57267
Request throughput (req/s): 8.30
Output token throughput (tok/s): 3713.84
Total Token throughput (tok/s): 12196.58
---------------Time to First Token----------------
Mean TTFT (ms): 173.75
Median TTFT (ms): 150.69
P99 TTFT (ms): 494.69
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 8.25
Median TPOT (ms): 7.36
P99 TPOT (ms): 43.46
---------------Inter-token Latency----------------
Mean ITL (ms): 7.36
Median ITL (ms): 6.77
P99 ITL (ms): 20.22
==================================================
Why is TP so effective?
With 2 GPUs, each GPU handles half the computation. The GPUs communicate via NVLink (for modern NVIDIA GPUs) or PCIe, which is fast enough to outweigh the communication overhead. The result: nearly 2x performance improvement.
When to use Tensor Parallelism:
- ✅ Multiple GPUs available (obviously!)
- ✅ Need lower latency for real-time applications
- ✅ Handling high concurrent request load
- ✅ Large batch sizes
- ✅ Models that don't fit in single GPU VRAM
- ✅ Best all-around optimization if you have the hardware
Torch Compile
PyTorch 2.0+ includes torch.compile(), which uses graph compilation to optimize the model's computational graph. Think of it as a Just-In-Time compiler that analyzes your model and generates faster CUDA kernels when you deploy Llama.
The compilation happens once at startup (adding ~1 minute to initialization), but then provides consistent performance improvements for the lifetime of the server.
Step 1: Enable Torch Compile
Set the environment variable before starting vLLM:
export VLLM_TORCH_COMPILE_LEVEL=3
Step 2: Serve with Torch Compile
Note: The first startup will take longer (~1 minute) while PyTorch compiles the model. Subsequent starts will be faster if you preserve the compilation cache.
vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 8000
Benchmark Results
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 32
Benchmark duration (s): 22.03
Total input tokens: 130803
Total generated tokens: 58083
Request throughput (req/s): 5.81
Output token throughput (tok/s): 2636.07
Total Token throughput (tok/s): 8572.50
---------------Time to First Token----------------
Mean TTFT (ms): 292.82
Median TTFT (ms): 255.79
P99 TTFT (ms): 783.74
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 12.15
Median TPOT (ms): 10.48
P99 TPOT (ms): 77.55
---------------Inter-token Latency----------------
Mean ITL (ms): 10.41
Median ITL (ms): 9.35
P99 ITL (ms): 28.45
==================================================
Why the small improvement?
vLLM already uses highly optimized CUDA kernels, so there's less room for torch.compile to improve. The benefits are more pronounced when:
- Combined with other optimizations (we'll see this later)
- Using specific GPU architectures (Hopper H100 benefits more)
- With consistent workload patterns over time
When to use Torch Compile:
- ✅ Long-running server deployments (amortize compilation cost)
- ✅ Consistent workload patterns
- ✅ Can tolerate initial compilation overhead (1-2 minutes)
- ✅ Combine with other optimizations for compounding benefits
- ❌ Avoid for short-lived inference jobs or frequent restarts
Prefix Caching
In many applications, when you deploy Llama, prompts share common prefixes. For example:
- RAG systems: Same system prompt + retrieved context + different user questions
- Chatbots: Same system instructions + different conversations
- Few-shot learning: Same examples + different test inputs
Prefix caching stores the computed KV cache for these common prefixes, so vLLM doesn't have to recompute them for every request. Think of it like browser caching: load once, reuse many times.
Example:
Prefix (cached): "You are a helpful assistant. Answer questions based on the following context: [5000 tokens of context]"
Suffix (computed): "What is the capital of France?"
Without prefix caching, vLLM processes all 5000+ tokens for every request. With prefix caching, it only processes the last sentence!
Enable Prefix Caching
vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--enable-prefix-caching
Benchmark Results
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 32
Benchmark duration (s): 21.92
Total input tokens: 130803
Total generated tokens: 58318
Request throughput (req/s): 5.84
Output token throughput (tok/s): 2660.84
Total Token throughput (tok/s): 8628.92
---------------Time to First Token----------------
Mean TTFT (ms): 271.63
Median TTFT (ms): 232.63
P99 TTFT (ms): 784.83
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 12.02
Median TPOT (ms): 10.39
P99 TPOT (ms): 64.40
---------------Inter-token Latency----------------
Mean ITL (ms): 10.40
Median ITL (ms): 9.32
P99 ITL (ms): 29.05
==================================================
Important Note: This benchmark uses random prompts without common prefixes, hence we are seeing minimal gains. In real-world scenarios with repeated prefixes, you'll see much more dramatic improvements:
The benefit scales with prefix length: longer shared prefixes = bigger savings.
When to use Prefix Caching:
- ✅ RAG systems with consistent system prompts and context
- ✅ Chatbots with fixed instructions or personas
- ✅ Few-shot learning with consistent examples
- ✅ Any scenario with repeated prompt prefixes (>100 tokens)
- ✅ Essential for production RAG deployments
- ❌ Less beneficial if every request has unique prompts
Combining Optimizations to Deploy Llama for Different Scenarios
The real power when you deploy Llama comes from combining multiple optimizations. Different applications have different priorities, so let's explore optimized configurations for common use cases.
Low TTFT for RAG/Chatbot Applications When You Deploy Llama
Goal: Minimize time to first token for a responsive user experience
Target Use Case: Production chatbot or RAG system where users expect instant responses
Configuration Strategy:
- ✅ Tensor Parallelism (faster prefill)
- ✅ Prefix Caching (skip redundant computation)
- ✅ High GPU memory utilization (larger KV cache for batching)
Command:
vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 2 \
--enable-prefix-caching \
--gpu-memory-utilization 0.9
Benchmark Results
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 32
Benchmark duration (s): 15.45
Total input tokens: 130803
Total generated tokens: 57375
Request throughput (req/s): 8.29
Output token throughput (tok/s): 3714.30
Total Token throughput (tok/s): 12182.12
---------------Time to First Token----------------
Mean TTFT (ms): 177.27
Median TTFT (ms): 160.10
P99 TTFT (ms): 485.39
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 8.68
Median TPOT (ms): 7.44
P99 TPOT (ms): 45.14
---------------Inter-token Latency----------------
Mean ITL (ms): 7.40
Median ITL (ms): 6.79
P99 ITL (ms): 20.18
==================================================
Analysis
Excellent results compared to baseline:
- ✅ Mean TTFT: 301.70ms → 177.27ms (41.24% faster)
- ✅ P99 TTFT: 786.34ms → 485.39ms (38.27% faster)
- ✅ Mean TPOT: 11.96ms → 8.68 ms (26.81% faster)
- ✅ Throughput: 8,674 → 12,182 tok/s (40.44% increase)
This configuration provides snappy responses (sub-200ms TTFT) that feel nearly instantaneous.
Important Note: Since we are performing the benchmarks on the same machine where the vLLM instance is running, network latency will be zero. In a production environment, network latency will be added based on where your server is located. Add expected network latency to your TTFT measurements for realistic production estimates.
Maximum Throughput for Batch Processing
Goal: Process maximum tokens per second for offline batch processing
Target Use Case: Processing large datasets, content generation pipelines, or batch inference tasks where total throughput matters more than individual request latency
Configuration Strategy:
- ✅ INT4 Quantization (frees VRAM for larger batches)
- ✅ Tensor Parallelism (parallel computation)
- ✅ Large batch parameters (maximize GPU utilization)
- ✅ High memory utilization (squeeze every bit of VRAM)
Command:
vllm serve hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4 \
--host 0.0.0.0 \
--port 8000 \
--quantization awq_marlin \
--tensor-parallel-size 2 \
--max-num-batched-tokens 8192 \
--max-num-seqs 256 \
--gpu-memory-utilization 0.95 \
--dtype half
Parameter Explanation:
- --max-num-batched-tokens 8192: Maximum tokens processed in a single batch
- --max-num-seqs 256: Maximum number of sequences batched together
Benchmark Command
vllm bench serve \
--model hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4 \
--host 0.0.0.0 --port 8000 \
--random-input-len 1024 \
--random-output-len 512 \
--num-prompts 2000 \
--max-concurrency 500
Why are we making more concurrent requests?
Earlier, our benchmark used only 32 concurrent requests. This configuration shines with much higher concurrency (100-500 concurrent requests), where:
- Larger batch sizes mean more efficient GPU utilization
- Quantization reduces memory bottlenecks
- TP provides computational headroom
Benchmarks
============ Serving Benchmark Result ============
Successful requests: 2000
Maximum request concurrency: 500
Benchmark duration (s): 124.33
Total input tokens: 2043842
Total generated tokens: 873653
Request throughput (req/s): 16.09
Output token throughput (tok/s): 7026.82
Total Token throughput (tok/s): 23465.50
---------------Time to First Token----------------
Mean TTFT (ms): 13750.92
Median TTFT (ms): 15958.78
P99 TTFT (ms): 20694.14
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 39.79
Median TPOT (ms): 36.00
P99 TPOT (ms): 215.70
---------------Inter-token Latency----------------
Mean ITL (ms): 34.43
Median ITL (ms): 20.55
P99 ITL (ms): 222.00
==================================================
Analysis:
This configuration is optimized for maximum batch processing:
- ✅ Throughput: 8,674 → 23465 tok/s (170.527% highest in this test)
However, the TTFT increases drastically here, making it unusable for real-time applications.
Real-World Batch Scenario:
With 200+ concurrent requests:
- This config can achieve 15,000-25,000 tok/s
- Processes thousands of documents per hour
- Maximizes cost efficiency (tokens per dollar)
When to use this configuration:
- ✅ Batch processing pipelines
- ✅ High concurrency workloads (>100 concurrent requests)
- ✅ Cost optimization (maximize throughput per GPU)
- ✅ Offline processing where latency doesn't matter
- ❌ Avoid for real-time user-facing applications
Comprehensive Benchmark Comparison
Let's summarize all the optimizations we've tested to help you choose the right configuration:
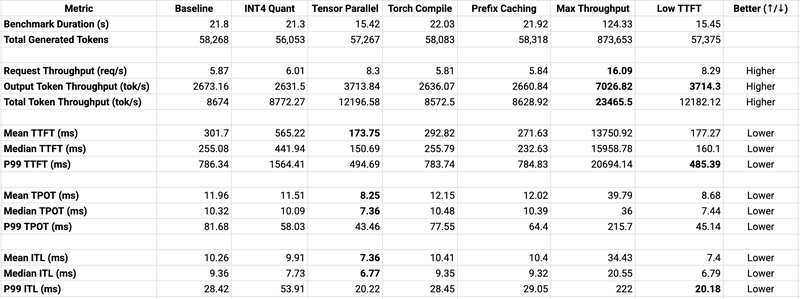
Key Takeaways
- Best Overall: Tensor Parallelism (if you have 2>= GPUs)
- Best for Low VRAM: INT4 Quantization (works on 24GB GPUs)
- Best for RAG/Chatbots: TP + Prefix Caching
- Best for Batch: Quantization + TP + Large batch sizes
- Smallest Improvement: Torch Compile (but free performance boost)
Best Practices and Tips
Memory Management
vLLM's memory usage consists of three main components:
- Model Weights: Fixed size (~16GB for FP16, ~4GB for INT4)
- KV Cache: Dynamically allocated for active requests (largest variable)
- Activations: Temporary memory during computation
Preventing OOM (Out of Memory) Errors:
If you encounter OOM errors, adjust these parameters:
vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct \
--gpu-memory-utilization 0.9 \
--max-model-len 4096
- --gpu-memory-utilization 0.9: Reserve 10% of VRAM for CUDA overhead (default: 0.9)
- --max-model-len 4096: Reduce context window to free KV cache memory
Batch Size Optimization
Batch size directly impacts the latency/throughput trade-off:
For Maximum Throughput:
vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct \
--max-num-batched-tokens 8192 \
--max-num-seqs 128
For Minimum Latency:
vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct \
--max-num-batched-tokens 2048 \
--max-num-seqs 16
Tuning Guide:
- High throughput: Increase both parameters (more batching)
- Low latency: Decrease both parameters (less batching)
- Memory constraints: Reduce `--max-num-batched-tokens` first
Context Length Considerations
Llama 3.1 8B supports up to 128K tokens, but most applications don't need this:
vllm serve meta-llama/Meta-Llama-3.1-8B-Instruct \
--max-model-len 4096
KV Cache Memory Impact:
- 2048 tokens: ~1-2GB KV cache per request
- 4096 tokens: ~2-4GB KV cache per request
- 8192 tokens: ~4-8GB KV cache per request
- 32768 tokens: ~16-20GB KV cache per request
Recommendation: Set --max-model-len to the highest value you actually need, not the model's maximum. This frees VRAM for more concurrent requests.
Conclusion
Throughout this comprehensive guide, we've explored deploying and optimizing Llama 3.1 8B on NVIDIA GPUs using vLLM. We've achieved impressive performance improvements:
- 42% faster TTFT with Tensor Parallelism (301.70ms → 173.75ms)
- 75% reduction in memory usage with INT4 quantization (16GB → 4GB)
- 170.527% throughput increase combining TP and INT4 quantization (8,674 → 23465 tok/s)
- 41.24% TTFT improvement for RAG/chatbot configurations (301.70ms → 177.27ms)
These are substantial gains that can meaningfully improve user experience and reduce infrastructure costs. For further model optimization and deployment, you can check out SimpliSmart model deployment documentation. Simplismart’s smart inference engine picks the best config possible for your use case, avoiding the painstaking process of trying each configuration yourself. Hence, instead of spending weeks optimizing your inference infrastructure and months maintaining it, you can focus on building your application. Visit Simplismart platform to try it out and see the performance difference yourself.
For more deployment guides, optimization strategies, and best practices, check out the Simplismart blog.
Additional Resources
- SimpliSmart Documentation
- vLLM Documentation



