

OpenAI made headlines in August 2025 when they open-sourced their first GPT class models since GPT-2: the GPT-OSS models. With GPT-OSS 120B parameter model delivering performance that matches proprietary models like OpenAI's o4-mini while being completely open-weight, it is a significant moment for the AI community. This powerful reasoning model comes pre-quantized with MXFP4, making it surprisingly efficient for deployment.
In this comprehensive guide, we'll walk through how to deploy GPT-OSS 120B on NVIDIA H100 GPUs using vLLM, covering everything from single-GPU deployments with memory optimization to scaling it to multi-GPU for production workloads. While this guide focuses on the 120B parameter model, it's worth noting that OpenAI also released a smaller model; the 20b variant, which is an excellent choice for teams targeting consumer hardware or with more constrained resources.
Architecture Breakdown of GPT-OSS 120B
Before diving into deployment, let’s inspect what’s under the hood of the GPT-OSS 120B model. This is a sparse Mixture of Experts (MoE) model with 128 experts, with 4 active experts during inference.. Despite having 120B total parameters, only 5.13B parameters are activated at a time, making it surprisingly efficient.
Key Highlights:
- Pre-quantized with MXFP4 for optimal GPU memory efficiency and faster inference.
- Strong Performance: Comparable to OpenAI o3-mini on knowledge and reasoning benchmarks, and competitive with o4-mini on tool calling and health-related queries.
- Open-Weight & Permissive Apache 2.0 License: Allows full customization and commercial deployment without any restrictions.
- Agentic Capabilities: Supports function calling, web browsing, Python code execution, and structured outputs—ideal for advanced automation use cases.
- Multilingual Support: Supports 14 languages (Arabic, Bengali, Chinese, French, German, Hindi, Indonesian, Italian, Japanese, Korean, Portuguese, Spanish, Swahili, Yoruba) with performance close to OpenAI o4-mini.

Source: https://artificialanalysis.ai/leaderboards/models
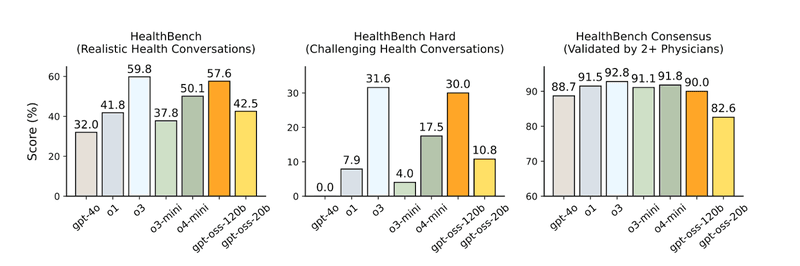
Source: https://arxiv.org/abs/2508.10925
Prerequisites
Hardware Requirements
- Minimum: Single NVIDIA H100 Node (80GB VRAM)
- Recommended: Two or more H100 (Multi-GPU setup is recommended for even better performance)
Software Requirements
- Ubuntu 18.04+ or similar Linux distribution
- NVIDIA drivers (version 525+)
- CUDA 11.8 or 12.1+
- Python 3.10-3.12
Environment Setup
Step 0: Accessing Your H100 Instance
Most developers don't have H100s readily available, as the initial hardware investment can be substantial ( if you do, congratulations on being GPU-rich! 🤗) , so you'll need to access cloud-hosted instances. Popular options include AWS p5.xlarge instances, Google Cloud A3 instances, or specialized GPU cloud providers. In this guide we are using an 8xH100 cluster.
# SSH into your cloud instance
ssh -i your-key.pem ubuntu@your-h100-instance
Step 1: Verify NVIDIA Driver Installation
Most cloud GPU instances come with NVIDIA drivers and CUDA pre-installed. Let's verify everything is working:
nvidia-smi
Expected output should show your H100 GPU(s) with driver version 535+ and CUDA 12.0+:
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.247.01 Driver Version: 535.247.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA H100 80GB HBM3 On | 00000000:0F:00.0 Off | 0 |
| N/A 27C P0 70W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA H100 80GB HBM3 On | 00000000:10:00.0 Off | 0 |
| N/A 29C P0 75W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 2 NVIDIA H100 80GB HBM3 On | 00000000:41:00.0 Off | 0 |
| N/A 29C P0 70W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 3 NVIDIA H100 80GB HBM3 On | 00000000:44:00.0 Off | 0 |
| N/A 27C P0 75W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 4 NVIDIA H100 80GB HBM3 On | 00000000:86:00.0 Off | 0 |
| N/A 27C P0 70W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 5 NVIDIA H100 80GB HBM3 On | 00000000:87:00.0 Off | 0 |
| N/A 28C P0 76W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 6 NVIDIA H100 80GB HBM3 On | 00000000:B8:00.0 Off | 0 |
| N/A 28C P0 68W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 7 NVIDIA H100 80GB HBM3 On | 00000000:BB:00.0 Off | 0 |
| N/A 28C P0 75W / 700W | 0MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
Step 2: Python Environment Setup
Create a dedicated directory and virtual environment for our deployment:
Note: vLLM recommends using uv for Python environment management, but we'll use the standard venv approach for broader compatibility.
Create project directory and install python development tools
mkdir ~/gpt-oss-120b && cd ~/gpt-oss-120b
sudo apt-get update && sudo apt-get install -y python3.10-dev
Step3: vLLM Installation
1. Install vLLM package
pip install vllm
2. Verify installation
vllm --version
It should show a message like this:
INFO 09-16 07:21:52 [__init__.py:241] Automatically detected platform cuda.
0.10.1.1
Pro Tip: vLLM has recently released v1 alpha, which offers a 1.7x speedup with architectural improvements including zero-overhead prefix caching and enhanced multimodal support. While we're using the latest stable version for this guide, consider exploring vLLM v1 for better performance.
Deploy GPT-OSS 120B on a Single GPU
Initial Deployment Attempt
Let's start with the most straightforward GPT-OSS deployment:
vllm serve openai/gpt-oss-120b
When running the vllm command for the first time, downloading gpt-oss to your server will take a couple of minutes.
If you encounter an Out of Memory (OOM) error, don't worry!
The default configuration is optimized for maximum context length, which may exceed single 80GB GPU H100’s memory limits.
An example OOM error in the log looks like this:
(EngineCore_0 pid=674861) ERROR 09-11 13:54:02 [core.py:700] ValueError: No available memory for the cache blocks. Try increasing `gpu_memory_utilization` when initializing the engine.)
There’s still a way to make it work on a single GPU. Let’s give it a shot.
Memory-Optimized Single GPU Deployment
Here's the memory-optimized command to deploy GPT-OSS 120B on a single H100:
vllm serve openai/gpt-oss-120b \
--max-model-len 4096 \
--gpu-memory-utilization 0.9 \
--max-num-seqs 8
Configuration breakdown:
--max-model-len 4096: Limits context window to 4K tokens--gpu-memory-utilization 0.9: Uses 90% of available GPU memory--max-num-seqs 8: Limits concurrent sequences for stable performance
By default, vLLM spins up a FastAPI server at localhost:8000, which will come handy at the later stage when we’ll explore the inference part. With the model now being served, let’s give it a spin by running some performance benchmarks.
Single GPU Performance Benchmarking
vLLM also comes with a benchmarking module that provides valuable insights into the performance of our deployment.
Let's benchmark our single-GPU deployment:
vllm bench serve \
--model openai/gpt-oss-120b \
--host 0.0.0.0 \
--port 8000 \
--random-input-len 1024 \
--random-output-len 512 \
--num-prompts 128 \
--max-concurrency 32
Parameter Breakdown
--model openai/gpt-oss-120b: Specifies the model to benchmark. Here, we use the openai/gpt-oss-120b model.--host 0.0.0.0: Host IP where the vLLM server is running--port 8000: Port on which vLLM is serving--random-input-len 1024: Sets the length of the randomly generated input prompt tokens to 1024.--random-output-len 512: Sets the length of the randomly generated output tokens to 512.--num-prompts 128: Specifies the number of prompts to generate and benchmark during the test.--max-concurrency 32: Controls the maximum number of concurrent requests sent during the benchmark to simulate parallel load.
Performance metrics:
Here is the result we got from the single H100 GPU.
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 32
Benchmark duration (s): 27.92
Total input tokens: 130718
Total generated tokens: 15414
Request throughput (req/s): 4.58
Output token throughput (tok/s): 552.04
Total Token throughput (tok/s): 5233.56
---------------Time to First Token----------------
Mean TTFT (ms): 4419.27
Median TTFT (ms): 5584.28
P99 TTFT (ms): 7170.78
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 16.70
Median TPOT (ms): 14.59
P99 TPOT (ms): 31.18
---------------Inter-token Latency----------------
Mean ITL (ms): 12.57
Median ITL (ms): 9.53
P99 ITL (ms): 71.27
==================================================
Deploy GPT-OSS 120B on Multiple GPUs
For the demands of production environments, where high throughput and larger context lengths are critical, let’s deploy GPT-OSS 120B across multiple GPUs using tensor parallelism.
In tensor parallelism, individual layers of the model are split across multiple GPUs, allowing them to jointly process the model in parallel. This enables efficient utilization of GPU memory and compute resources, especially for large models that don’t fit on a single GPU.
vllm serve openai/gpt-oss-120b --tensor-parallel-size 2
Here, --tensor-parallel-size specifies the number of GPUs to use.
Key Considerations:
- Supported GPU Counts: vLLM's tensor parallelism requires an even number of GPUs, such as 2, 4 or 8.
- Single Node Deployment: This setup is ideal for single-node, multi-GPU configurations
For larger-scale deployments, consider using both tensor and data parallelism to efficiently utilize all available GPUs.
Multi-GPU Benchmarking
Let’s test the multi-GPU performance with the same load:
vllm bench serve \
--model openai/gpt-oss-120b \
--host 0.0.0.0 \
--port 8000 \
--random-input-len 1024 \
--random-output-len 512 \
--num-prompts 128 \
--max-concurrency 32
Performance metrics
============ Serving Benchmark Result ============
Successful requests: 128
Maximum request concurrency: 32
Benchmark duration (s): 11.65
Total input tokens: 130718
Total generated tokens: 17089
Request throughput (req/s): 10.99
Output token throughput (tok/s): 1467.27
Total Token throughput (tok/s): 12690.75
---------------Time to First Token----------------
Mean TTFT (ms): 260.51
Median TTFT (ms): 177.59
P99 TTFT (ms): 862.47
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 25.75
Median TPOT (ms): 24.31
P99 TPOT (ms): 62.79
---------------Inter-token Latency----------------
Mean ITL (ms): 17.08
Median ITL (ms): 11.41
P99 ITL (ms): 121.36
==================================================
Inference
REST API
Now let’s try simple GPT-OSS-120b API usage from an external device.
For external access, ensure your firewall allows access to port 8000
curl --location 'YOUR_SERVER_IP:8000/v1/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "openai/gpt-oss-120b",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Explain quantization to a 10 years old child."}
]
}'
Sample Response
{
"id": "chatcmpl-1a3ed8509768421cb7fd096b2e10e7d3",
"object": "chat.completion",
"created": 1758051496,
"model": "openai/gpt-oss-120b",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "**Imagine you have a giant box of crayons** \n\nYou love to draw pictures, and you have…",
"refusal": null,
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [],
"reasoning_content": "We need to explain quantization to a 10-year-old…"
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 92,
"total_tokens": 998,
"completion_tokens": 906,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"kv_transfer_params": null
}
Local Inference using OpenAI Python Client
Create a simple Python script in your instance to test your deployment:
# test_deployment.py
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="EMPTY" # vLLM doesn't require authentication by default
)
# Test Responses API (OpenAI's new format)
responses_result = client.responses.create(
model="openai/gpt-oss-120b",
instructions="You are a helpful AI assistant.",
input="What makes the simplismart.ai the fastest inference provider?",
)
print("\nResponses API Response:")
print(responses_result.output_text)
Run the script
python test_deployment.py
If the script runs without errors and displays the expected output, that means the deployment is working fine.
Advanced Configuration and Optimization
At Simplismart.ai, we know that every use case is unique. To achieve optimal performance, you'll need to tune deployment parameters to match your specific goals. Here are two examples of how you can tune vLLM to prioritize different metrics.
For high-throughput scenarios:
vllm serve openai/gpt-oss-120b \
--tensor-parallel-size 2 \
--max-num-seqs 64 \
--gpu-memory-utilization 0.90
For low-latency scenarios:
vllm serve openai/gpt-oss-120b \
--tensor-parallel-size 2 \
--max-num-seqs 8 \
--gpu-memory-utilization 0.75
Performance Comparison
vLLM vs Other Inference Engines
Recent benchmarks show that vLLM achieves 2.7x higher throughput and 5x faster TPOT (time per output token) on large language models, making it an excellent choice for production deployments.
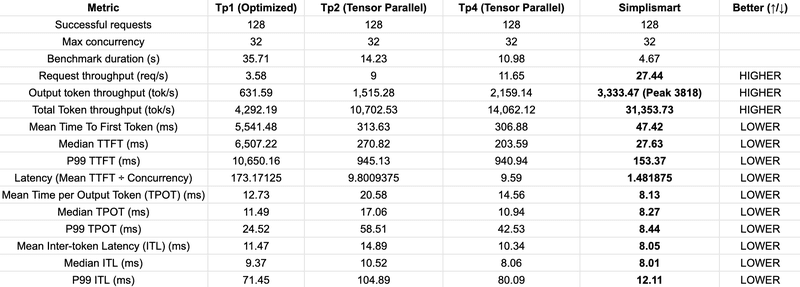
For further optimized model deployment, you can check out SimpliSmart model deployment documentation. Here is the the comparison table between normal vLLM deployments and Simplismart Note: vLLM and Simplismart benchmarks were conducted on a remote instance, in the same region as the vLLM and Simplismart servers.
Conclusion and Next Steps
You've now successfully deployed OpenAI's GPT-OSS 120B on H100 GPUs using vLLM! This setup provides you with a powerful, locally-controlled reasoning model.
Key takeaways:
- GPT-OSS 120B delivers exceptional performance with MXFP4 quantization
- Single H100 deployments work well for development with proper memory optimization
- Multi-GPU setups enable production-scale throughput and lower latency
- vLLM provides enterprise-grade serving capabilities with OpenAI-compatible APIs
Next steps to explore:
- Experiment with fine-tuning for domain-specific applications
- Implement caching strategies for improved response times
- Scale horizontally with multiple vLLM instances behind load balancers
- Monitor and optimize for your specific workload patterns
The open-source nature of GPT-OSS 120B opens up incredible possibilities for customization, local deployment, and cost-effective scaling. Whether you're building the next generation of AI applications or conducting cutting-edge research, this deployment foundation will serve you well.
Additional Resources



